카테고리 없음
XGboost와 Light GBM algorithm
_채리니_
2021. 4. 25. 22:00
XGboost는 트리기반 앙상블 기법입니다. 분류에 있어서 다른 알고리즘보다 좋은 예측 성능을 보여줍니다. (캐글 대회에서 우승을 몇번 했었습니다.)
XGBoost는 GBM기반이지만, 단점은 느리다는 것이고 장점은 적합 규제 부재등의 문제를 해결한 것 입니다.
Light GBM은 Gradient Boosting 프레임워크로 Tree 기반 학습 알고리즘입니다.
- Light라는 이름이 붙은 이유는? 메모리를 적게 사용하여 속도가 빠르기 때문입니다. (큰 사이즈의 데이터를 실행시킬때 적은 메모리를 차지합니다.)
- 왜 인기가 있는가? 결과의 정확도에 초점을 맞추기 때문입니다.
- 어떤 데이터에 사용해야 할까? 작은 데이터 세트에 적합하지 않습니다. overfitting에 민감하고 과적합하기 쉬운 모델입니다. 주로, 10,000개 이상의 데이터가 있을 때 사용하길 권합니다. 범주형 특징(categorical variable의 경우)의 자동 변환과 최적 분할을 수행합니다.
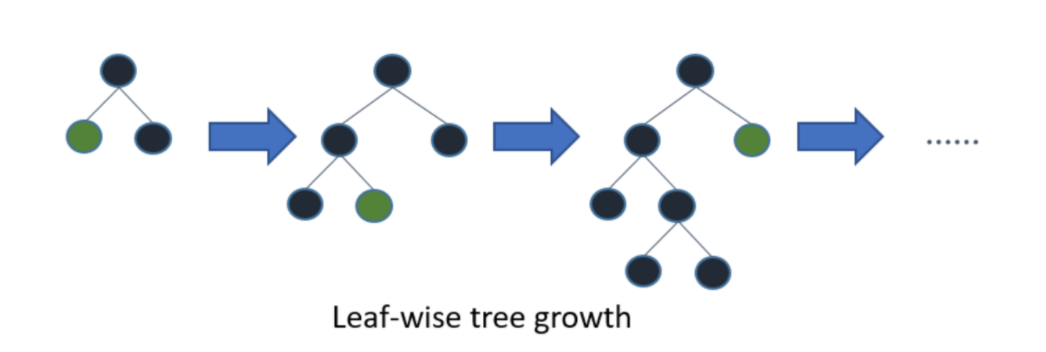
기존 Tree가 수직적(level-wise)으로 확장되는데 Light GBM은 수평적으로 확장됩니다. (Leaf-wise)
이를 확장하기 위해, Max delta loss를 가진 leaf를 선택합니다. (leaf-wise알고리즘이 level-wise알고리즘보다 더 많은 loss를 줄일 수 있습니다.)

100개 이상의 파라미터를 가지고 있는 모델!
하지만, 간략하게 주로사용하는 파라메터들에 대해서 논의해 보도록합니다.
- max_depth: Tree의 최대 깊이. 모델의 과적합을 줄이기 위해서는 model의 깊이를 줄입니다.
- min_data_in_leaf: leaf가 가지고 있는 최소한의 레코드수. (디폴트 = 20)
- feature_fraction: Boosting이 랜덤포레스트일 경우에 사용합니다. 예를들어, 0.8인 경우 GBM이 Tree를 만들때 매번, iteration 반복에서 파라미터 중에서 80프로를 랜덤하게 선택하는 것을 의미합니다.
- abagging_fraction: 매번 iteration을 돌때 사용되는 데이터 선택시 속도를 높이고 과적합을 방지해줍니다.
- early_stopping_round: 지나친 iteration을 막는데 사용합니다.
- lambda: regularization을 합니다.
- min_gain_to_split: 분기하기 위해 필요한 최소한의 gaain을 의미합니다.
- max_cat_group:카테고리수가 클때 과적합을 방지하는 분기포인트를 찾습니다.
nurilee.com/2020/04/03/lightgbm-definition-parameter-tuning/
LightGBM 이란? 그리고 Parameter 튜닝하기
LightGBM에 관한 좋은 medium 포스트가 있어서 한글로 번역한 내용을 공유드려봅니다 :) Pushkar Mandot의 원문 바로가기: 안녕하세요, 머신러닝은 이 세상에서 가장 빠르게 성장하는 분야입니다. 매일
nurilee.com