트랜스포머: 셀프어텐션 사용(단어간 장거리 종속성과 문맥 관계를 포착할 수 있게 하는 어텐션) 아키택처에서 파생된 AI 모델이며 사람의 언어를 이해 및 생성
종류
Language Modeling은 NLP의 하위분야로 '자동 인코딩 작업'과 '자기회귀 작업' 두가지 모델링 작업이 있음.
자동인코딩: 알려진 어휘에서 문장의 어느 부분이든 누락된 부분을 채우도록 모델에 요청. 예시로는 BERT. 트렌스포머의 인코더 부분에 해당. 마스크 없이 양방향 표현을 생성. 문장 분류 또는 토큰 분류에 주로 사용됨.
자기회귀(Autoregressive Language): 알려진 어휘에서 주어진 문장의 바로 다음에 가장 가능성 있는 토큰을 생성하도록 모델에 요청. 예시로는 GPT. 트렌스포머 모델의 디코더 부분에 해당
특징
2017년에 나온 트렌스포머는 seq2seq 모델이었음.
아래 두가지 요소를 가지고 있음.
인코더: 문장을 핵심구성 요소로 분리, 벡터화하고 어텐션을 이용해 텍스트 맥락을 이해(텍스트 이해가 뛰어남)
디코더: 수정된 형식의 어텐션을 사용해 다음에 올 최적의 토큰을 예측하고 텍스트 생성(텍스트 생성이 뛰어남)
이 둘을 사용하면 seq2seq 모델이 됨.
BERT는 인코더, GPT는 디코더만 있는 모델, T5는 둘을 조합한 모델.
1.1 LLM의 작동원리
사전훈련(pre-training)과 파인튜닝되는지에 따라 성능이 결정됨. LLM기반 모델들은 언어와 단어의 관계를 배우고 이해하려는 훈련을 받음.
Pre-training은 모델을 사전에 학습하는 것임. 예를 들면, BERT는 영어 위키백과(영어버전의 위키백과로 수집된 기사들)와 BookCorpus(다양한 장르의 소설, 비소설로 검증된 저자에 의해 영어로 작성된 문서들)에서 사전훈련 되었음.
또한, 두가지 모델로 학습되는데 '마스크된 언어모델링'(한 문장 안에서 토큰의 상호작용을 인식하도록)과 '다음문장예측'(문장들 사이에서 토큰이 서로 어떻게 상호작용하는지) 모델링 작업을 수행하는데 전자는 개별 단어 임베딩을 가르치기 위함이고 후자는 전체 텍스트 시퀀스를 임베딩하는 방법을 학습하기 위함.
전이학습(Transfer Learning)
LLM내에서 전이학습은 말뭉치에서 사전훈련한 LLM을 가져와 작업 특정 데이터로 모델의 파라미터를 업데이트함.
이미 특정 언어와 언어간의 관계를 사전에 학습해서 새로운 작업에 성능 향상을 가능하게 함.
비지도 학습으로 일반적인 개념을 가르치고, 지도학습으로 모델을 파인튜닝
파인튜닝(Fine-tunning)
특정 작업의 성능을 향상시키기 위한 조정
어텐션(Attention)
다양한 가중치를 다르게 할당하는 메커니즘. 가장 중요한 정보를 강조 가능해짐.
위 설명을 요약하자면,
LLM은 큰 말뭉치에서 사전훈련되고 작은 데이터셋으로 파인튜닝됨. 트랜스포머는 고도의 병렬처리가 가능하여 빠르며 토큰 간의 장거리 의존성과 관계를 어텐션을 사용해서 포착 가능함. 특히, 어텐션이 Internal world model과 사람이 식별할 수 있는 규칙을 학습하는데 가장 주요한측면으로 보여지고 있음.
임베딩(Embedding)
단어, 구절, 토큰의 수학적 표현
토큰 임베딩(토큰의 의미를 임베딩), 세그먼트 임베딩, 위치임베딩(위치를 임베딩)등 여러 종류의 임베딩이 존재함.
텍스트가 토큰화되면 각 토큰에 임베딩이 주어지고 그 값들이 더해짐. 어텐션이 계산되기 전에 초기 임베딩을 갖게됨.
토큰화(Tokenization)
텍스트의 가장 작은 이해단위인 토큰으로 분해하는 과정
LLM에서는 전통적인 NLP에서 사용한 불용어제거, 어간추출, 잘라내기 등과 같은 것들이 필요하지 않음.
out-of-vocaburary(OVV)구문을 어떻게 처리하나? 일단 더 작은 부분의 단어로 나눔.
1.2 가장 많이 활용되는 LLM
BERT, T5(Google), GPT(OpenAI)은 트렌스포머 기반 아키텍쳐
BERT(Bidirectional Encoder Representation from Transformers)
문장의 양방향 표현을 구성하기 위해 어텐션 메커니즘을 사용하는 자동 인코딩 모델
문장 분류와 토큰 분류 작업에 이상적.
Bidirectional: 자동 인코딩 언어 모델
Encoder: 트랜스포머에서 인코더만 활용
Representation: 어텐션을 활용
Transformers: 트랜스포머의 아키텍처를 활용
생성에 중점을 둔 느린 LLM에 비해 빠르게 처리 가능. 자유로운 텍스트 처리보다 대량의 말뭉치를 빠르게 분석하고 작업하는데 적합. 문서 분류나 요약보다는 사전훈련된 모델로 활용함.
GAN(Generative Adversarial Network)로 적대적 생성 모델이라고 합니다.
하나씩 뜯어서 보자면, 생성모델이라는 관점에서
머신러닝에서 만들어내는 예측 결과나, continuous variable의 interval prediction값이 아닌(가장 높은 확률 혹은 likelihood를 찾아내는 행위), 데이터의 형태를 만들어내는 모델입니다.
데이터의 형태는 분포 혹은 분산을 의미하고 데이터의 형태를 만들어 낸다는 것은 '실제적인 형태'를 갖춘 데이터를 만든다는 뜻입니다.
Ian Goodfellow 의 논문에 수록된 그림.
위 그림에서 보듯이, 기존에 분포를 학습해서 데이터의 형태를 찾아나가고 이를 만들어 내는 것입니다.
또한, 적대적 생성의 의미 측면에서는,
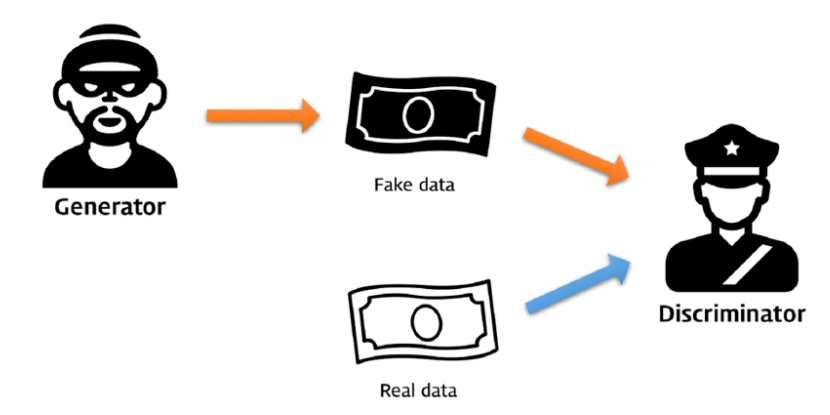
GAN의 핵심 아이디어로, 각각의 역할을 가진 두개의 모델로 진짜같은 가짜를 생성해주는 능력을 키워주는 것을 의미합니다.
예를 들어, 위조범이 가짜 지폐를 만들어내고, 경찰은 가짜지폐를 찾아내는 역할을 합니다. 더욱 더 서로가 위조지폐를 정교하게 만들고, 만들어진 위조지폐를 정확히 찾아내는 것으로 서로 적대적으로 능력을 키워주고 있습니다.
이런 아이디어에서부터 '적대적'이라는 용어가 붙게 되었습니다.
GAN 모델을 가장 쉽게 설명할 수 있는 그림. [출처 : https://files.slack.com/files-pri/T25783BPY-F9SHTP6F9/picture2.png?pub_secret=6821873e68]
2. GAN의 학습방법
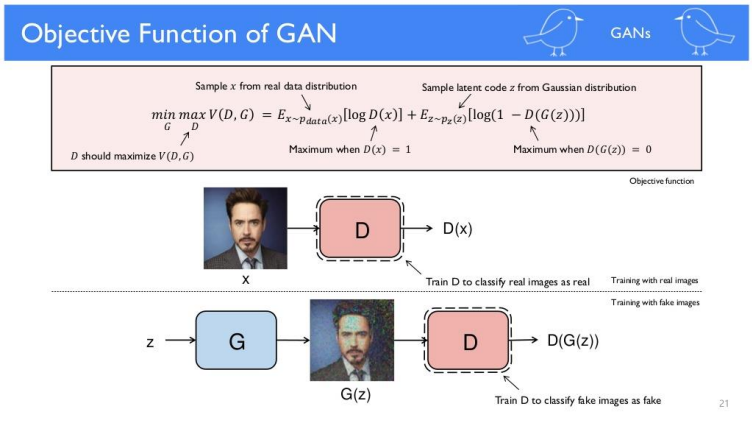
Discriminator는 CNN판별기처럼 네트워크 구성할 수 있습니다. Disciminator로 진짜 이미지는 1, 그렇지 않은 것은 0으로 학습을 시키고, z라는 랜덤백터를 넣어 Genarative학습을 시킨 이미지가 이미 학습된 D에 들어갔을때, 오로지 진짜 이미지로 판별할 수 있도록, G를 학습시키는 것입니다.
G는 random한 noise를 생성해내는 vector z를 noise input으로 받고 D가 판별해내는 real image를 output으로 하는 neural network unit을 생성합니다.
GAN의 코어 모델은 D와 G두개이고, mnist이미지를 real image로 D한테 '진짜'임을학습시키고,
vector z와 G에 의해 생성된 Fake Image가 가짜라고 학습을 시켜 총 두번의 학습을 거칩니다.
이때, 따로 학습되는 것이 아니라 1번의 과정에서 real image와 fake image를 D의 x input으로 합쳐서 학습합니다.
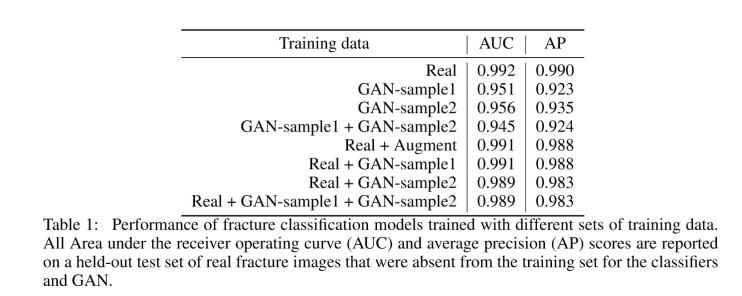
3. GAN을 이용해 영상 이미지를 만들고 AUC를 비교해보자.
Real image만 사용했을때, AUC가 0.99정도 나왔고, 그 외에 GAN으로 만들어진 sample들로 학습했을때와, real과 gan을 적절히 섞어서 학습했을때 높은 AUC를 끌어낼 수 있었습니다.
그리고 실제 값과 모델이 학습한 값이 동일한지 correct_prediction으로 해주고,
accuracy에서는 맞거나 틀린것들에 대한 평균을 내준다.
6. Run
with tf.Session() as sess:
print('start....')
sess.run(tf.global_variables_initializer())
for i in range(10000):
trainingData, Y = mnist.train.next_batch(64)
sess.run(train_step, feed_dict={X:trainingData, Y_Label:Y})
if i%100:
print(sess.run(accuracy, feed_dict={X:mnist.test.images, Y_Label:mnist.test.labels}))
C에서 이루어지는 연산이므로 Sess를 얻어와서 진행을 하고 변수들을 tf.global_variables_initializer()을 사용해서 꼭 초기화해주어야 합니다.
위의 코드는 10000번의 학습으로 64개의 배치크기만큼 가져오고 100번마다 test데이터셋을 통해 정확도를 확인한 것입니다.
일반적으로 대중화된, 아이리스 데이터 등으로 데스크탑에서 손쉽게 돌려볼 수 있는 머신러닝 자료들은 데이터를 통째로 IDE로 불러들인 다음 메모리상에 올려두고 작업하는 방식이었을 것이다. 모델을 학습함에 있어서도 모든 트레이닝 데이터셋의 결과값을 한번에 구한 뒤, 데이터셋과 쌍이 맞는 레이블과의 차이를 구해서 비용함수를 한번에 개선하는 방식의 학습을 n-iterative 하게 진행하였을 것이다. 하지만 머신러닝을 진행함에 있어서 데이터의 크기는 언제든지 늘어나게 된다. 아마 실전의 대부분은, 한 개의 데스크탑에서 불러올 수 없는 양의 데이터가 대부분일 것이다. 이런 경우 R 혹은 Python등의 툴로는 데이터를 메모리에 올려놓고 한번에 처리하기가 힘들어진다. 그렇게 되면 모델을 학습하는 경우에도 트레이닝 데이터를 쪼개서 여러 번 넣어야 하고, 프로그래머 식으로 말하자면 전자는 for loop를 한번 돌지만 후자는 '트레이닝 데이터들' 이라는 loop가 하나 더 생기는 것이라고 할 수 있다. 전자의 경우를 일괄 처리 방식, 일명 batch 방식이라고 한다. 후자는 online processing 혹은 mini batch라고 한다. 딥러닝의 영역으로 들어가게 된다면, 데이터의 양이 기하급수적으로 증가하기 때문에(딥러닝까지 가지 않더라도) mini batch 시스템을 이용하여 모델을 학습하는 것은 거의 필수적인 일이 되어버렸다.