------------------------------------------------------------
테이블 정리에 유용한 도구 - Pivot table from Pandas
------------------------------------------------------------
Pivot table이란?
pivot table은 엑셀에서 자주 보이던 함수를 인용해서 만든 함수이다.
data frame에서 column명으로 index를 주면 index안에 어떤 내용물을 기준으로
나머지 (숫자 값만을 가진)열의 데이터를 평균(default)내어준다.
예를 들면,
pd.pivot_table(df,index='Name')인덱스도 여러개 지정할 수 있다. Name, Rep, Maneger가 각각 하나씩 표현되도록 테이블을 만들고 그것들의 평균을 내서 보여준다.
pd.pivot_table(df,index=['Name','Rep','Manager'])보고싶은 values를 정할 수도 있다.
pd.pivot_table(df,index=['Name','Rep','Manager'],values='Price')
위에서 언급했듯이 기본값은 평균을 내어준다. 하지만 분석메서드를 바꾸고 싶다면
aggfunc이라는 옵션을 추가한다. np.sum은 numpy에 있는 총합계 함수이다.
pd.pivot_table(df,index=['Name','Rep','Manager'],values='Price',aggfunc=np.sum)위와같이 진행하고 np.sum과 np.mean값을 동시에 얻고 얻은 값들중 margin을 NaN으로 채우지 않고, 값을 주고 싶다면 아래와 같이 수행한다.
pd.pivot_table(df,index=['Name','Rep','Manager'],values='Price',aggfunc=[np.sum,np.mean],fill_value=0,margins=True)
2. 서울시 범죄 검거율을 위해 pivot table과 다양한 함수 사용해보기
우선 사용할 library를 import하고 데이터도 불러온다.
import numpy as np
import pandas as pd
crime_anal_police = pd.read_csv('C:/Users/USER-PC/Documents/DataScience_followingbook/data/02. crime_in_Seoul.csv',thousands=',',encoding='euc-kr')
crime_anal_raw = pd.read_csv('C:/Users/USER-PC/Documents/DataScience_followingbook/data/02. crime_in_Seoul_include_gu_name.csv',thousands=',',encoding='utf-8')구별로 분석할 것이기 때문에 pivot table을 이용해서 경찰서를 구별로 합계내본다.
crime_anal_raw.head()
crime_anal = pd.pivot_table(crime_anal_raw,index='구별',aggfunc=np.sum)
crime_anal.head()그리고 각 범죄별 검거율을 만들어주고 필요없는 범죄 검거건수는 모두 없애준다.
crime_anal['강간검거율']=crime_anal['강간 검거']/crime_anal['강간 발생']*100
crime_anal['강도검거율']=crime_anal['강도 검거']/crime_anal['강도 발생']*100
crime_anal['살인검거율']=crime_anal['살인 검거']/crime_anal['살인 발생']*100
crime_anal['절도검거율']=crime_anal['절도 검거']/crime_anal['절도 발생']*100
crime_anal['폭력검거율']=crime_anal['폭력 검거']/crime_anal['폭력 발생']*100
del crime_anal['강간 검거']
del crime_anal['강도 검거']
del crime_anal['살인 검거']
del crime_anal['절도 검거']
del crime_anal['폭력 검거']
crime_anal.head()
결과가 이상한 것들이 보일텐데 이유는 전년도 검거건수가 포함되서 100 이상의 비율을 갖는 것이 본인다.
이를 100으로 모두 대체해준다.
con_list = ['강간검거율','강도검거율','살인검거율','절도검거율','폭력검거율']
for column in con_list:
crime_anal.loc[crime_anal[column]>100,column] = 100
crime_anal.head()그리고 '절도 발생'에서 '발생'이라는 단어를 rename을 이용해서 삭제할 것입니다.
3. 데이터를 정규화 하기
각 범죄당 건수가 너무 다양해서 이를 보기 좋게 만들기 위해 정규화를 수행할 것이다.
이때 데이터 전처리에 아주 잘 사용되는 library가 있는데 scikit learn module이다.
머신러닝이나 데이터 분석전에 전처리에 아주 유용하게 사용된다.
from sklearn import preprocessing
col = ['강간','강도','살인','절도','폭력']
x=crime_anal[col].values
min_max_scaler = preprocessing.MinMaxScaler()
x_scaled = min_max_scaler.fit_transform(x.astype(float))
crime_anal_norm = pd.DataFrame(x_scaled, columns=col, index = crime_anal.index)
col2 = ['강간검거율','강도검거율','살인검거율','절도검거율','폭력검거율']
crime_anal_norm[col2]=crime_anal[col2]
crime_anal_norm.head()그 다음엔 이전에 CCTV데이터를 불러와서 인구수와 CCTV개수를 crime_anal_norm에 붙일 것이다.
또한, 전체 범죄의 합을 '범죄'로 만들고 검거율의 합을 '검거'로 만들어 column을 추가할 것이다.
result_CCTV = pd.read_csv('C:/Users/USER-PC/Documents/DataScience_followingbook/data/01. CCTV_result.csv',encoding='utf-8',index_col='구별')
result_CCTV.head()
crime_anal_norm[['인구수','CCTV']]=result_CCTV[['인구수','소계']]
crime_anal_norm['범죄']=np.sum(crime_anal_norm[col],axis=1)
crime_anal_norm['검거']=np.sum(crime_anal_norm[col2],axis=1)
crime_anal_norm.head()
-------------------------------------
분석에 유용한 도구 - seaborn
-------------------------------------
import matplotlib.pyplot as plt
%matplotlib inline
import seaborn as sns
x = np.linspace(0,14,100)
y1= np.sin(x)
y2 = 2*np.sin(x+0.5)
y3 = 3*np.sin(x+1.0)
y4 = 4*np.sin(x+1.5)
plt.figure(figsize=(10,6))
plt.plot(x,y1,x,y2,x,y3,x,y4)
plt.show()* 팁: 항사 module을 불러올때 주의해야할 점은 class를 불러와야한다는 것이다.
module만 불러오면
'module' object is not callable <= 이와같은 에러가 나타나는데 이유는 class를 불르지 않았기 때문이다.
우선 위와같은 데이터로 코드를 만들면

위와같은 예쁜 그래프가 만들어진다.
(1). seaborn 기능 - whitegrid
sns.set_style('whitegrid')
plt.figure(figsize=(10,6))
plt.plot(x,y1, x,y2, x,y3, x,y4)
plt.show()
whitegrid를 추가하여 plot할 수 있다.
(2). seaborn 기능
우선 tips데이터를 seaborn에서 예제로 불러온다.
import matplotlib.pyplot as plt
import numpy as np
import seaborn as sns
sns.set_style('whitegrid')
%matplotlib inline
tips= sns.load_dataset('tips')
tips.head(5)그리고 x축은 비정형데이터 값 y축은 정형데이터값으로 boxplot을 수행할 것이다.
plt.figure(figsize=(10,6))
sns.boxplot(x='day',y='total_bill', data=tips)
plt.show()
hue 라는 옵션으로 구분자를 줄 수 있다.
plt.figure(figsize=(10,6))
sns.boxplot(x='day',y='total_bill',hue='smoker',data=tips, palette = 'Set3')
plt.show()
lmplot으로 데이터를 scatter해주고 regression한 직선을 그어주며 유효범위 ci도 잡아주는 함수이다.
sns.set_style('darkgrid')
sns.lmplot(x='total_bill',y='tip',data=tips, size=7)
plt.show()
(3). pivot
새로운 데이터를 불러와서
pivot함수를 사용할 것인데
사용 용도는 아래와 같다.
pivot('a','b','c'): a를 인덱스로 b를 컬럼으로 해당되는 c의 데이터를 불러와서 없는 값은 NaN을 준다.
flights = sns.load_dataset('flights')
flights.head(5)
flights = flights.pivot('month','year','passengers')
flights.head()
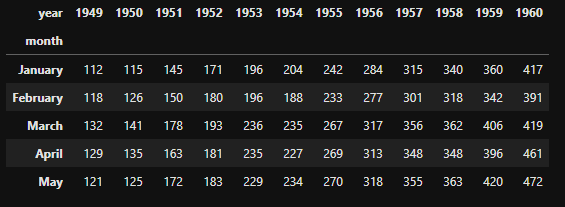
heatmap함수로 달과 년도에 따라 승객이 얼마나 있는지 heatmap으로 표현한다.
heatmap의 특징은 표현하러는 모든 데이터가 완벽히 갖춰져있고 index와 column이 하나로만 정해져 있다면 그대로 사용할 수 있다.
만일 원하는 columns에 대해서 정해진 index들이 보고 싶다면,
데이터를 줄 때, dataset[colum]의 형식으로 데이터를 heatmap안에 주는 것이 좋다.
plt.figure(figsize=(10,6))
sns.heatmap(flights, annot=True, fmt='d')
plt.show()
마지막으로 유명한 데이터 iris로 종에 따라서 데이터 분포를 보려고 한다.
sns.set(style='ticks')
iris = sns.load_dataset('iris')
iris.head(10)
sns.pairplot(iris, hue = 'species')
plt.show()hue옵션으로 species에 따른 데이터 분포를 각각 보려고 한다.
결과는 아래와 같다.

4. seaborn모듈로 범죄 데이터를 시각화하기
일단 한글 폰트 문제를 해결하고 pairplot으로 강도,살인,폭력간의 관계를 알아볼 것입니다.
kind는 'scatter'와 'reg' 두가지가 있는데 reg=regression plot을 수행합니다.
import platform
path = 'C:/Windows/Fonts/malgun.ttf'
from matplotlib import font_manager, rc
if platform.system() == 'Windows':
font_name = font_manager.FontProperties(fname=path).get_name()
rc('font',family=font_name)
sns.pairplot(crime_anal_norm, vars=['강도','살인','폭력'],kind='reg',size=3)
plt.show()vars를 사용해서 특정변수에 대해 pairplot을 수행하면, x,y축 모두 그 변수들을 사용하여 plot하고
x_vars, y_vars를 특정 변수로 준다면 x,y가 그 변수를 이용해 축을 형성한다.
그렇다면, x축을 검거율로 하고 y축을 각 구별로 해서 heatmap을 그리면 어떤 결과가 나올까?
검거율을 위해 검거 column의 최댓값을 100으로 놓고 다른 검거값들을 변환해준다.
그리고 검거가 높은 값을 기준으로 값들을 sorting해서
각 구별로 여러 검거율의 현황을 보고자 한다.
tmp_max = crime_anal_norm['검거'].max()
crime_anal_norm['검거']=crime_anal_norm['검거']/tmp_max*100
crime_anal_norm_sort = crime_anal_norm.sort_values(by='검거',ascending=False)
crime_anal_norm_sort.head()
target_col = ['강간검거율','강도검거율','살인검거율','절도검거율','폭력검거율']
plt.figure(figsize=(10,10))
sns.heatmap(crime_anal_norm_sort[target_col],annot=True, fmt='f', linewidth=.5)
plt.show()

---------------------------------------------
지도를 자유자제로 그리는 folium library
---------------------------------------------
위도와 경도를 이용해 지도를 그리고, zoom을 얼만큼의 비율로 할것인지도 설정한 뒤에,
지도 위에 원하는 구역을 동그라미치고 색상으로 표시하고
특정로케이션에 마크를 주고 싶다.
import folium
map_2 = folium.Map(location=[45.5236,-122.6750], tiles = 'Stamen Toner', zoom_start = 13)
folium.Marker([45.5244,-122.6699], popup='The Waterfront').add_to(map_2)
folium.CircleMarker([45.5215,-122.6261], radius = 50, popup='Laurelhurst Park',color='#3186cc',fill_color='#3186cc',).add_to(map_2)
map_2
json파일에 경로를 담아서 choropleth명령으로 json파일과 데이터를 입력하고 key_on옵션으로 지도에 id를 알려준 다음에 취업률에 따라 color를 fill합니다.
'데이터분석 > 예제로 데이터분석' 카테고리의 다른 글
| 서울시 구별 CCTV 현황분석 (0) | 2020.02.18 |
|---|