생존분석이란?
잘 정의된 시점으로부터 event가 일어나기까지 걸린 시간을 분석하고 예측하는 분석이다.
event는 주로 사망, 질병악화, 기계고장 등이 있다. 따라서, 시간과 수치값을 예측하는 것이기 때문에 회귀모델로 적용되나, 일반적인 통계 모형에 적용할 수 없는 생존분석만의 특징이 있다.
- 생존 분석으로 연구 집단의 특이변화를 직관적으로 확인 가능하다.
Censoring
- Right censoring: 연구 종료 전 사망 혹은 연구 종료 후 생존
- Left censoring: 연구 시작 전 질환을 이미 보유 혹은 측정한 생존 시간보다 실제 생존 시간이 더 긴 경우

생존분석 방법 1) Kaplan-Meier 추정방법
사건에 따른 사건 발생률을 계산하는 생존분석 방법이다.
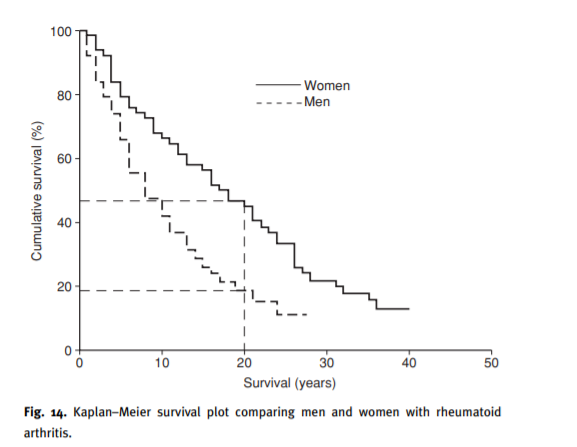
아래 그림은 survival plot으로 시간에 따른 생존율을 파악할 수 있고
두 그룹간의 유의미한 차이를 보기위해 Log-Rank test혹은 willcoxon test를 수행한다.
생존분석의 특징
1) 레이블은 최소 2개를 갖는다.
=> 사건 발생까지의 시간과 사건 발생여부
예시) 신장이식 환자에 대한 생존분석을 한다고 가정하고, 환자 10명이 있다. 10명 모두 수술받은 날짜를 알아내는 것(시작점)이 가능하지만, 계속 지켜보는 것은 불가능하다. 그렇지만 그들의 생존시간과 사망정보를 기록해야한다.
하지만, event발생 전에 종료된 데이터들을 censored data라고 부른다. 하지만 끝까지 관찰된 샘플은 uncensored data라고 부른다.
대표적인 모델로 Cox-proportional hazard model이 있다. (아래 관련 링크 첨부)
https://chealin93.tistory.com/search/survival
모델을 평가하는 방법
생존 시간의 예측 정확도를 알고싶을때는, MSE를 사용하고 사망여부를 고려한 생존시간 예측정확도를 알고 싶다면 C-index를 사용한다.
C-index란?
1) 샘플들의 생존 시간을 오름차순으로 나열하고, 사건이 관찰된 각 샘플들보다 오래 생존한 샘플들의 개수를 모두 더한 총합
2) 샘플들을 예측된 생존시간의 오름차순으로 나열하고, 사건이 관찰된 각 샘플들보다 오래 생존할 것으로 올바르게 예측된 샘플들의 개수를 모두 더한 총합
1과 2의 비율로 나타난다.

c-index는 0.0~1.0 사이의 값을 갖는다. 1.0에 가까울수록 정확히 예측한다고 해석하고, 0.5에 가까울수록 무작위로 예측한다고 평가한다. 해석이 AUROC(Area Under Receiver Operating Characteristic curve)와 비슷하여, c-index를 AUROC의 회귀분석용으로 확장한 것이라는 이야기도 있다.
'통계분석 > 의학통계' 카테고리의 다른 글
| 두군의 수가 맞지 않을때: Propensity Score Matching and univariate Cox ph regression (0) | 2021.05.10 |
|---|---|
| Cox proportional hazard regression HRplot해석 (0) | 2020.10.21 |
| Cox proportional hazard model (0) | 2020.09.09 |




