cohort 모집조건은 index date를 설정하는 것과, 환자를 걸러낼 필터역할을 하는 inclusion/exclusion criteria로 나누어져 있다.
연구 목적에 맞는 집단의 정의를 내려 index date를 설정하고 나면, index date는 다른 inclusion이나 exclusion조건에 영향을받아서는 안된다. 또한, 그런 조건들이 index date에 영향을 주는 것들이라면 처음부터 index date에 함께 넣는 것을 고민해봐야한다.
Background: symptom-physical signs과 objective tests의 조화에 딥러닝을 적용하였을 때, 어른 천식환자들의 초기 진단을 예측하는데 머신러닝보다 더 나은 성능을 보였다.
Methods: Kindai 대학병원에 non-specific respiratory symptoms을 가지고 처음 방문한 566명의 환자의 후향적 데이터를 이용. logistic, SVM, DNN사용.
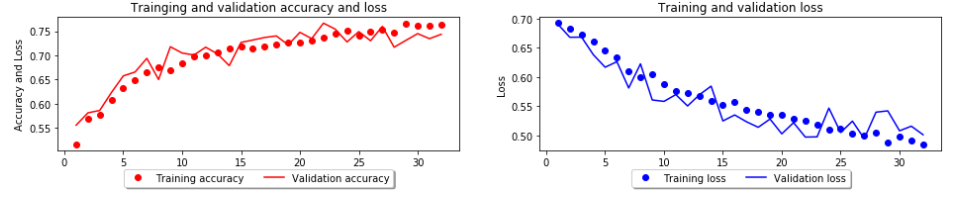
Results: symptom-physical sign만으로 모델을 돌리면 대략 DNN,SVM,logistic이 0.65정도의 acc를 갖는데, biochemical findings, lung function test, bronchial challenge test를 추가하여 모델을돌리면 DNN은 0.98의 높은 정확도를 보이고 SVM: 0.82, logistic은 0.94wjdeh.
Conclusions: classical machine learning에 비해 adult asthma를 진단하는데 매우 용이하다.
1. Introduction
외적인 기침, 숨쉬기 어려움, 쎅쎅거림 등으로 판단하면 30프로정도는 misdiagnosis
복합적 질환으로서 gold standard가 존재하지 않는다.
이전에 symptom sign score를 만듦
그렇지만 약한 증상을 가진 사람들은 추가 진단에 의해 diagnosis해야함.
linear regression model을 사용해서 accuracy를 보니 symptom sign score만놓고 보면 70정도.
*equivocal: 모호한
*non-specific: 불특정의, 일반적인
*peripheral: 말초의, 중요하지 않은 부분의
2. Methods
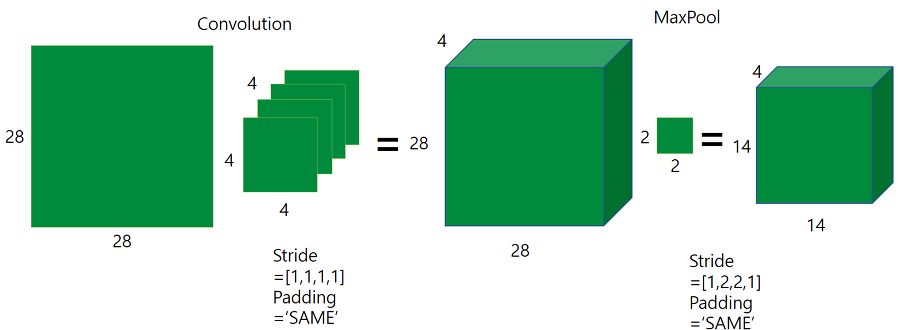
classifier: logistic analysis, SVM and DNN
초기에 tensorflow로 변수 초기화하고, 뭐 딥러닝해서 해주는 파라미터 튜닝등을 거쳤다. 블라블라
*만일 GPU를 갖고 있지 않으면 아마존 AWS, 마이크로소프트 Azure 및 IBM SoftLayer를 비롯한 클라우드 서비스 제공업체에서 GPU하나를 사용하는 방법도 있다.
1. 사용하려는 GPU의 driver를 다운받는다. 차례대로 NVIDIA® GPU drivers, CUDA® Toolkit, CUPTI, cuDNN을 깔아줍니다. 나의 컴퓨터에는 GTX 1080 Ti가 들어가 있어서 이에 맞춰 GTX 1080 Ti drivers, CUDA 8.0 Toolkit과 cuDNN을 CUDA 8.0에 맞추어 다운로드 받아주었다.
2. tensorflow의 딥러닝을 위해 GPU를 사용하는 것으로 tensorflow-gpu를 다운받는다. 간혹 다운을 받는데
import pandas as pd
import sys
import numpy as np
import matplotlib.pyplot as plt
%matplotlib inline
pd.__version__
# print(sys.version) #Python 내에서 현재 python version확인용
우리가 사용할 library중 테이블을 잘 정리하고 분석에 용이한 Pandas라는 library에 대해 간략히 정리할 것이다.
우선 pandas의 기본 데이터 유형은 Series인데 어떤 데이터 유형이던 담을 수 있다.
s = pd.Series([1,3,4,np.nan,6,8]) #pandas 의 기초유형
s
또한, 날짜 관련 데이터 유형이 있다. periods를 이용해서 지정한 2013년01월01일부터 2013년 01월06일까지 dates variable에 지정된다.
dates = pd.date_range('20130101',periods=6)
dates
#pd.date_range 함수를 쓰면 모든 날짜/시간을 일일히 입력할 필요없이 시작일과 종료일 또는 시작일과 기간을 입력하면 범위 내의 인덱스를 생성해 준다.
DataFrame을 만들고 여러가지 테이블 관련 함수를 사용하거나 문자와 숫자로 인덱싱을 할 수 있다.
*주의 할 점은 인덱싱을 할 때, 숫자나 문자로 인덱싱이 된다. 하지만 loc함수에서도 문자로만 indexing이 되고 iloc은 숫자로 인덱싱이 된다.
copy()함수를 쓰는 이유는 그냥 다른 변수에 원래 변수를 할당해주면 동일한 주소를 갖게되므로
copy()함수를 써서 다른 주소로 변수를 할당해주어야한다.
#조건에 맞는 테이블 찾기
df[df>0]
#변수 복사
df2 = df.copy()
#column하나 추가
df2['E']=['one','one','two','three','four','three']
#E컬럼에서 two와 four를 갖고있는 조건의 df2 데이터프레임 반환
df2[df2['E'].isin(['two','four'])]
#apply는 apply함수로 어떤 함수를 전체 데이터프레임에 적용함
df.apply(np.cumsum)
#간단하게 함수를 만들때 lambda를 사용
df.apply(lambda x: x.max()-x.min())
dist = lambda x: x.max()-x.min()
concat은 행기준으로 데이터를 병합하는 것이고 열 기준으로 묶기 위해서는 axis를 1로 변경해준다. 그런데 자주 사용 안 할 것 같다.
result = pd.concat([df1,df2,df3],keys=['x','y','z']) #keys를 설정하면 다중 인덱스가 됨
result.index
result.index.get_level_values(0)
result = pd.concat([df1,df4],axis=1) #concat은 index를 기준으로 date를 합침
result = pd.concat([df1,df4],axis=1,join='inner') #concat은 index를 기준으로 date를 합침
result = pd.concat([df1,df4],axis=1,join_axes=[df1.index]) #concat은 index를 기준으로 date를 합침
result = pd.concat([df1,df4],ignore_index=True) #concat은 index를 기준으로 date를 합침
result
대신 merge라는 것을 사용할 것이다.
left=pd.DataFrame({'key':['k0','k4','k2','k3'],
'A':['a0','a1','a2','a3'],
'B':['b0','b1','b2','b3']})
right=pd.DataFrame({'key':['k0','k1','k2','k3'],
'C':['c0','c1','c2','c3'],
'D':['d0','d1','d2','d3']})
left
right
pd.merge(left,right,on='key')
pd.merge(left,right,how='left',on='key')
pd.merge(left,right,how='right',on='key')
pd.merge(left,right,how='outer',on='key')
pd.merge(left,right,how='inner',on='key')
data_result = pd.merge(CCTV_seoul,pop_seoul,on='구별')
data_result.head()
del data_result['2013년도 이전']
del data_result['2014년']
del data_result['2015년']
del data_result['2016년']
data_result.head()
data_result.set_index('구별',inplace=True)
data_result.head()
이제 정렬이 어느 정도 되었으니 각 column별로 얼마나 관계를 띄는지 확인해보려 한다.
그리고 실제 값과 모델이 학습한 값이 동일한지 correct_prediction으로 해주고,
accuracy에서는 맞거나 틀린것들에 대한 평균을 내준다.
6. Run
with tf.Session() as sess:
print('start....')
sess.run(tf.global_variables_initializer())
for i in range(10000):
trainingData, Y = mnist.train.next_batch(64)
sess.run(train_step, feed_dict={X:trainingData, Y_Label:Y})
if i%100:
print(sess.run(accuracy, feed_dict={X:mnist.test.images, Y_Label:mnist.test.labels}))
C에서 이루어지는 연산이므로 Sess를 얻어와서 진행을 하고 변수들을 tf.global_variables_initializer()을 사용해서 꼭 초기화해주어야 합니다.
위의 코드는 10000번의 학습으로 64개의 배치크기만큼 가져오고 100번마다 test데이터셋을 통해 정확도를 확인한 것입니다.