'데이터분석 > MIT 머신러닝 강의' 카테고리의 다른 글
| supervised learning - linear regression (week4 concept) (0) | 2022.05.10 |
|---|
| supervised learning - linear regression (week4 concept) (0) | 2022.05.10 |
|---|
Let’s start with an example: Suppose you're given a dataset that contains the size (in terms of area) of different houses and their market price. Your goal is to come up with an algorithm that will take the size of the house as its input and return its market price as the output.
In this example, the input variable i.e the size of the house, is called the independent variable (X), the output variable i.e house price is called the dependent variable (Y), and this algorithm is an example of supervised learning.
In supervised learning, algorithms are trained using "labeled" data (in this example, the dependent variable - house price, is considered a label for each house), and trained on that basis, the algorithm can predict an output for instances where this label (house price) is not known. "Labeled data" in this context simply means that the data is already tagged with the correct output. So in the above example, we already know the correct market price for each house, and that data is used to teach the algorithm so that it can correctly predict the house price for any future house for which the price may not be known.
The reason this paradigm of machine learning is known as supervised learning, is because it is similar to the process of supervision that a teacher would conduct on the test results of a student on an examination, for example. The answers the student gives (predictions) are evaluated against the correct answers (the labels) that the teacher knows for those questions, and the difference (error) is what the student would need to minimize to score perfectly on the exam. This is exactly how machine learning algorithms of this category learn, and that is why the class of techniques is known as supervised learning.
There are mainly 2 types of supervised learning algorithms:
In this lecture, we will be learning about regression algorithms, which obviously find great use in the machine learning prediction of several numerical variables we would be interested in estimating, such as price, income, age, etc.
Linear Regression is useful for finding the linear relationship between the independent and dependent variables of a dataset. In the previous example, the independent variable was the size of the house and the dependent variable its market price.
This relationship is given by the linear equation:
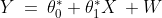
Where

is the constant term in the equation,

is the coefficient of the variable
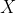
,
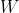
is the difference between the actual value
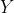
and the predicted value (

).
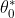
and

are called the parameters of the linear equation, while
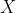
and

are the independent and dependent variables respectively.
With given
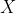
and
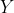
in the training data, the aim is to estimate

and

in such a way that the given equation fits the training data the best. The difference between the actual value and the predicted value is called the error or residual. Mathematically, it can be given as follows:
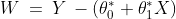
In order to estimate the best fit line, we need to estimate the values of
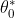
and

which requires minimizing the mean squared error. To calculate the mean squared error, we add the square of each error term and divide the sum with the total number of records:
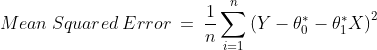
The equation of that best fit line can be given as follows:
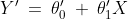
Where
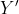
is the predicted value,

are the estimated parameters.
This equation is called the linear regression model. The above explanation is demonstrated in the below picture:

Before applying the model over unseen data, it is important to check its performance to make it reliable. There are a few metrics to measure the performance of a regression model.

| Maximum Likelihood and Empirical Risk Estimation (week4 concepts) (0) | 2022.05.10 |
|---|
예를 들어, Accuracy가 80인 경우 100개중 80개의 정답을 맞춘 것 입니다.
여기서 중요한 것은 무조건 balanced data의 경우에만 이 지표를 사용하는 것이 맞습니다.
예를 들어, 암환자는 1명, 암환자가 아닌 사람은 999명인 상황에서 우리가 만든 모델이
'암환자가 아닌 환자로 모두 판별하는 모델'로 만들어 졌다면,
Accuracy는 전체 1000명중 999명을 암환자가 아닌것으로 판단하였기 때문에 99%의 Accuracy값을 갖게됩니다.
이말은, 쉽게 말해 암환자가 아니라고만 말하고 찍어도 99프로 이상의 정답률을 낸다는 것입니다.
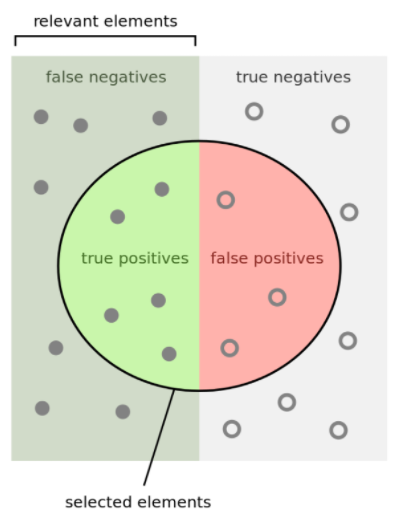
Precision(정밀도)는 PPV(Positive Positive Value)와 같은 의미를 가진 용어입니다.
의미를 살펴본다면, 내 알고리즘이 Positive(양성)이라고 예측한 것 들중에 실제로 Positive인 것들이 몇개나 되는지를 나타냅니다.
Recall(재현율)은 Sensitivity(민감도)와 같은 의미를 가진 용어입니다.
실제 Positive인 데이터들 중 내 알고리즘이 Positive라고 예측한 것이 몇개나 되는지를 나타냅니다.

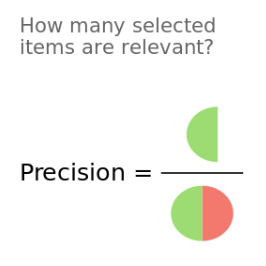
F1-score는 Precision과 Recall을 모두 고려하고 싶을때 사용하는 지표로 약간씩 다른 관점에서 Positive를 얼마나 잘 예측하는지 성능평가하는 값입니다.
보통은, ROC커브를 그려 AUC로 성능을 평가하지만, Precision과 Recall을 이용한 경우는 Precision-Recall Curve를 그려서 확인합니다.
Threshold에 따라, Precision과 Recall은 trade-off관계를 가지며 threshold에 의한 함수라는것을 알 수 있습니다.
Threshold를 조정하여 Precision-Recall Plot을 그리는 것을 설명해놓은 좋은 블로그를 공유해 놓습니다.
https://ardentdays.tistory.com/20
Precision-Recall Curves 설명 및 그리기(Python)
Precision-Recall Curves 설명 및 그리기(Python) Goal 이 페이지에서는 Precision-Recall Curve가 무엇이고, 어떻게 그려지는지 알아보겠습니다. 이를 위해서 필요하다고 생각되는 Precision과 Recall, 그리..
ardentdays.tistory.com
| Feature selection? sklearn을 활용하면 (0) | 2023.07.19 |
|---|---|
| Sampling 방법 (0) | 2023.04.28 |
| 데이터 불균형 문제를 대하는 법 - Sampling 방법론 (0) | 2021.04.13 |
| 표준화(standardization)와 정규화(normalization) (0) | 2021.01.27 |
| PCA - 주성분 분석 (0) | 2020.11.16 |
| 자동화 시스템 구축을 위한 AutoML (0) | 2023.03.30 |
|---|---|
| Decision tree (0) | 2022.06.29 |
| Sensitivity, Specificity, PPV, NPV (0) | 2021.04.26 |
| Upsampling방법 - SMOTE 알고리즘 (0) | 2021.04.09 |
| imbalance classification 다루는 방법 2 (0) | 2021.04.05 |
참고하기 좋은 블로그
쉽게 이해하는 민감도, 특이도, 양성예측도
쉽게 이해하는 민감도, 특이도, False Positive, False Negative, 양성예측도 민감도 (Sensitivity), 특이도(Specificity), 양성 예측도(Positive Predictive Value, PPV) 는 바로 무언가를 예측하는 상황에서..
3months.tistory.com
| Decision tree (0) | 2022.06.29 |
|---|---|
| LASSO 이해하기 (0) | 2021.06.28 |
| Upsampling방법 - SMOTE 알고리즘 (0) | 2021.04.09 |
| imbalance classification 다루는 방법 2 (0) | 2021.04.05 |
| Tree 모델과 R tree library (0) | 2021.01.27 |
abundant class(주로 정상데이터)와 rare class(이상데이터 그룹)의 비율이 1:99와 같이 극단적인 경우가 발생하는 경우,
크게 두가지 방법으로 모델의 잘못된 판단을 막을 수 있습니다.
1. sampling을 하는 것
2. 모델의 cost를 주어 모델 내에서 개선하는 방법
이번 포스팅에서는 sampling중 down-sampling과 up-sampling의 방법론들을 다룰 것 입니다.
Under-sampling의 장점은 필요없는 데이터를 지우기 때문에, 계산시간이 빠르지만 단점은 지워진 데이터들로 인해 정보손실이 발생할 수 있습니다.
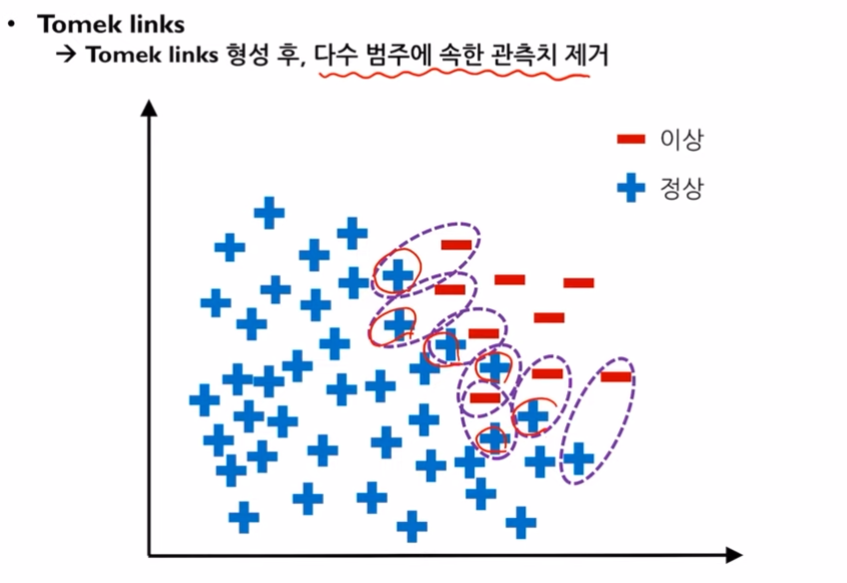
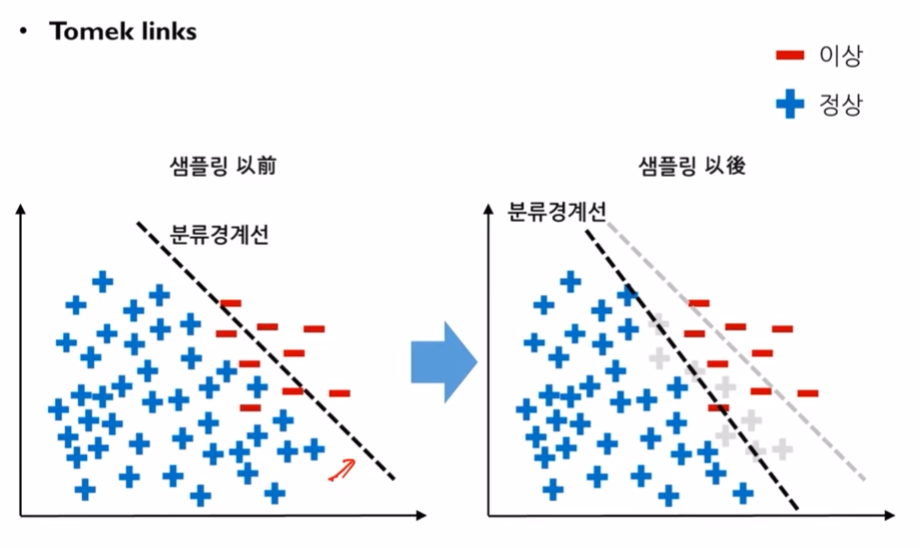
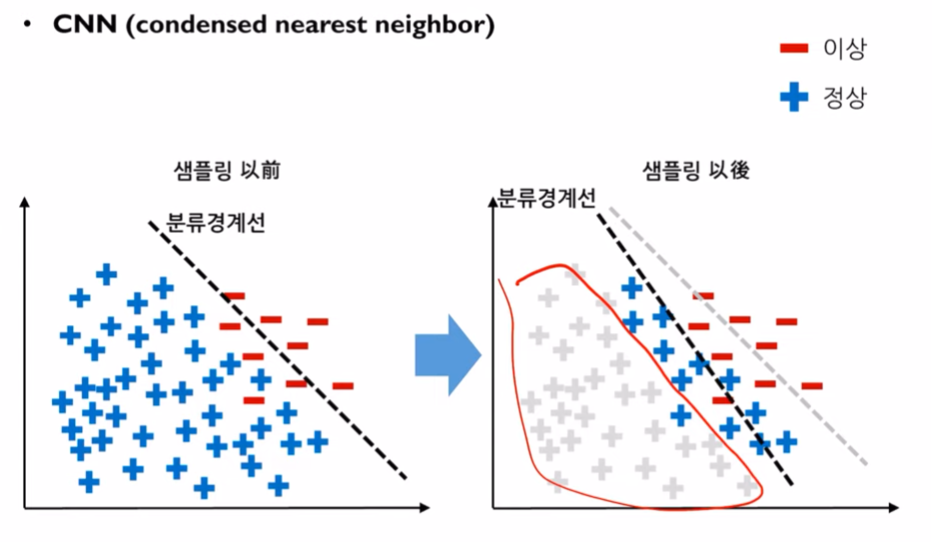
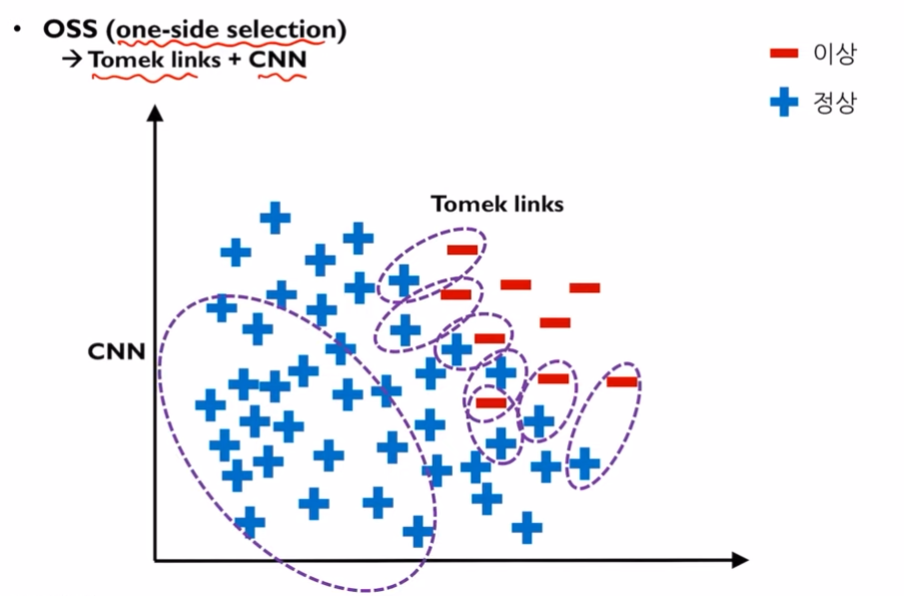
단점: 소수클래스에 과적합이 생길 수 있습니다.
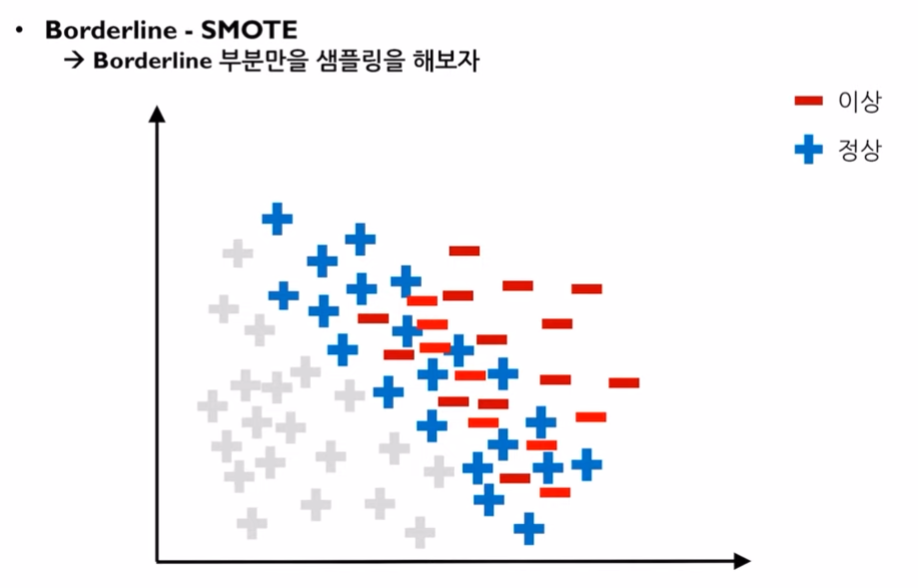
여기서?
컴퓨터가 Boarderline을 판단하는 방법은, k를 정해 그룹핑을 하여 k개의 데이터가 모두 소수 관측치라면 이를 'safe 관측치'라고 부릅니다. 그리고 이것은 boarderline이 될 수 없습니다.
하지만, 다른 k개의 그룹을 했을때, 다수 관측치가 k/2이상이라면 이를 boarderline이라고 하며 'danger 관측치'라고 부릅니다. k개의 그룹에서 다수의 데이터가 또 너무 많이 존재할 경우 이를 'noise 관측치'라고 합니다.
따라서, Boarderline SMOTE sampling의 경우에는 danger 관측치에서 SMOTE sampling을 하는것을 말합니다.
<인공지능공학소의 김성범 소장님의 강의를 참고하여 작성합니다. >
python 비대칭 데이터 문제 해결:
비대칭 데이터 문제 — 데이터 사이언스 스쿨
데이터 클래스 비율이 너무 차이가 나면(highly-imbalanced data) 단순히 우세한 클래스를 택하는 모형의 정확도가 높아지므로 모형의 성능판별이 어려워진다. 즉, 정확도(accuracy)가 높아도 데이터 갯
datascienceschool.net
| Feature selection? sklearn을 활용하면 (0) | 2023.07.19 |
|---|---|
| Sampling 방법 (0) | 2023.04.28 |
| 평가지표 (1) Accuracy와 Precision and Recall (0) | 2021.08.02 |
| 표준화(standardization)와 정규화(normalization) (0) | 2021.01.27 |
| PCA - 주성분 분석 (0) | 2020.11.16 |
down-sampling은 데이터 수가 많다고 생각될 경우 사용을 하지만, 보통 데이터수가 많으면 많을수록 좋기때문에
up-sampling을 down-sampling보다 선호합니다.
unsupervised machine learning model과 다르게 supervised model은 outcome의 확률분포를 학습하지 않습니다.
따라서, training data의 outcome비율을 1:1로 맞추기 위해 up-sampling을 해주어도 절대! test data의 outcome 비율을 변경하기 위해 test data도 up-sampling을 해주지 않습니다!
'데이터의 비율을 달리하여 학습한 모델인데 test data도 비슷한 분포를 띄어야 학습결과가 좋게 나온다?'라고 쉽게 오해할 수 있습니다.
하지만, 기본적으로 test data는 변경하여 사용하는 것이 아닐 뿐더러
1) 모델이 학습할 때, supervised model의 경우 outocme의 비율을 학습하지 않습니다.
upsampling의 목적은 imbalance한 데이터를 학습할 경우 모델이 한쪽 class로 판단하는 모델로 빠르게 도달하지 않도록 방해하는 역할을 합니다. up-sampling은 rare class의 데이터들을 복원추출하여 데이터를 늘리는것이기 때문에 다량의 학습데이터를 학습하는 효과를 주는것이 아닌, rare class의 특성을 반영한 데이터들이 늘어나서 over-fitting이 됩니다.
2) test data의 분포를 모델이 체크하지 않습니다.
training data로 모델을 만들고 나서 test data를 이용해 모델의 성능을 평가하는데 이때, test data는 한개씩 들어가서 이를 (binary의 경우) 1,0중에 판단하여 결과값만 내기때문에 outcome의 분포는 상관하지 않습니다.
Up-sampling의 하나의 종류로, k 최근접 이웃 method를 이용한 방법입니다.
우선, k 최근접 이웃 모델을 사용할때처럼 rare class의 데이터들중 하나의 데이터를 선택하고 그 주변에 얼마나 많은 k개의 이웃을 선택할 것인지 정해줍니다.
예를 들어, k가 5개이면, 정해진 중심으로부터 5개의 이웃만 고려를 할것입니다.
그리고 간단히, SMOTE알고리즘이 구동되는 방식을 보자면,
X는 선택한 점, X(nn)은 그 주변에 선택된 하나의 근접이웃, u는 균등분포입니다.

예를 들면, X가 (5,1)이고 X(nn)이 (2,3)인 경우 X(nn)부터 X까지의 거리를 표현하면 (-3,2)가 됩니다.


두 점사이 거리에서 0부터 1사이의 값이 랜덤으로 곱해져서 둘 사이에 위치하는 새로운 데이터가 생성이 될 것입니다.
이 방법은 rare class의 있는 데이터를 고르는것이 아닌, 비슷한 데이터를 생성해내기 때문에 약간의 차이는 있지만
그래도 over-fitting의 문제를 고려해야합니다.
reference: www.youtube.com/watch?v=Vhwz228VrIk
| LASSO 이해하기 (0) | 2021.06.28 |
|---|---|
| Sensitivity, Specificity, PPV, NPV (0) | 2021.04.26 |
| imbalance classification 다루는 방법 2 (0) | 2021.04.05 |
| Tree 모델과 R tree library (0) | 2021.01.27 |
| Cross-validation (교차검증) (0) | 2021.01.07 |
포스팅 목적: 의학도나 방사선사들의 훈련에는 많은 영상이 필요하나, 구조적 법적 문제로 대량의 영상을 공유하기가 쉽지 않습니다. 데이터의 양이 적어 해결되지 않는 문제들을 개선하고자 공부하였고 이 내용을 포스팅합니다.
reference:
논문: Towards generative adversarial networks as a new paradigm for radiology education
참고 영상:
1시간만에 GAN(Generative Adversarial Network) 완전 정복하기
NAVER Engineering | 발표자: 최윤제(고려대 석사과정) 발표일: 2017.5. Generative Adversarial Network(GAN)은 2014년 Ian Goodfellow에 의해 처음으로 제안되었으며, 적대적 학습을 통해 실제 데이터의 분포를 추정하
tv.naver.com
1. GAN이란?
GAN(Generative Adversarial Network)로 적대적 생성 모델이라고 합니다.
하나씩 뜯어서 보자면, 생성모델이라는 관점에서
머신러닝에서 만들어내는 예측 결과나, continuous variable의 interval prediction값이 아닌(가장 높은 확률 혹은 likelihood를 찾아내는 행위), 데이터의 형태를 만들어내는 모델입니다.
데이터의 형태는 분포 혹은 분산을 의미하고 데이터의 형태를 만들어 낸다는 것은 '실제적인 형태'를 갖춘 데이터를 만든다는 뜻입니다.
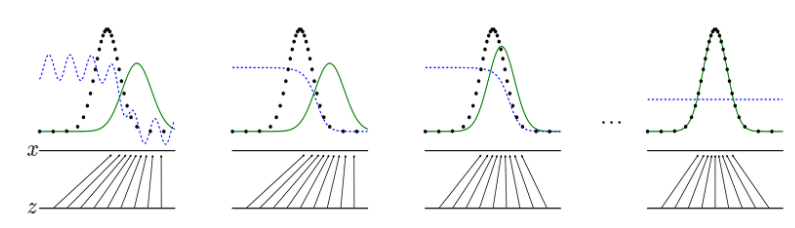
위 그림에서 보듯이, 기존에 분포를 학습해서 데이터의 형태를 찾아나가고 이를 만들어 내는 것입니다.
또한, 적대적 생성의 의미 측면에서는,
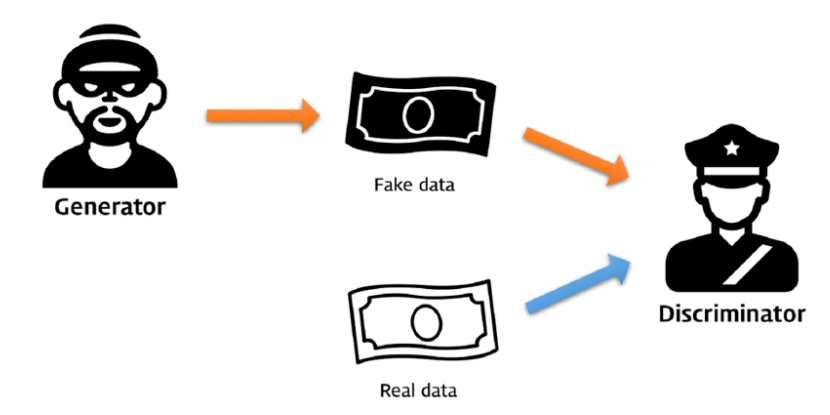
GAN의 핵심 아이디어로, 각각의 역할을 가진 두개의 모델로 진짜같은 가짜를 생성해주는 능력을 키워주는 것을 의미합니다.
예를 들어, 위조범이 가짜 지폐를 만들어내고, 경찰은 가짜지폐를 찾아내는 역할을 합니다. 더욱 더 서로가 위조지폐를 정교하게 만들고, 만들어진 위조지폐를 정확히 찾아내는 것으로 서로 적대적으로 능력을 키워주고 있습니다.
이런 아이디어에서부터 '적대적'이라는 용어가 붙게 되었습니다.
2. GAN의 학습방법
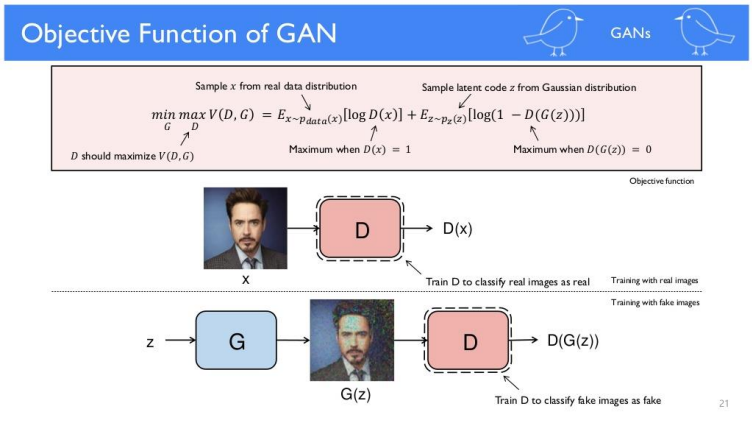
Discriminator는 CNN판별기처럼 네트워크 구성할 수 있습니다. Disciminator로 진짜 이미지는 1, 그렇지 않은 것은 0으로 학습을 시키고, z라는 랜덤백터를 넣어 Genarative학습을 시킨 이미지가 이미 학습된 D에 들어갔을때, 오로지 진짜 이미지로 판별할 수 있도록, G를 학습시키는 것입니다.
G는 random한 noise를 생성해내는 vector z를 noise input으로 받고 D가 판별해내는 real image를 output으로 하는 neural network unit을 생성합니다.
GAN의 코어 모델은 D와 G두개이고, mnist이미지를 real image로 D한테 '진짜'임을학습시키고,
vector z와 G에 의해 생성된 Fake Image가 가짜라고 학습을 시켜 총 두번의 학습을 거칩니다.
이때, 따로 학습되는 것이 아니라 1번의 과정에서 real image와 fake image를 D의 x input으로 합쳐서 학습합니다.
3. GAN을 이용해 영상 이미지를 만들고 AUC를 비교해보자.
Real image만 사용했을때, AUC가 0.99정도 나왔고, 그 외에 GAN으로 만들어진 sample들로 학습했을때와, real과 gan을 적절히 섞어서 학습했을때 높은 AUC를 끌어낼 수 있었습니다.
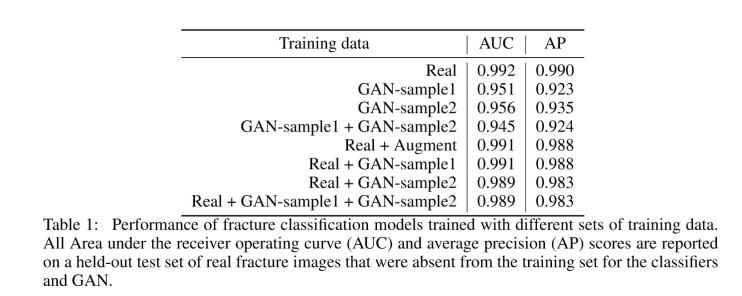
reference논문을 요약하자면,

| LLM(Large Language Model) (1) | 2024.11.13 |
|---|---|
| Knowledge distillation & Calibration (0) | 2024.05.20 |
| CNN으로 개와 고양이 분류하기 (1) | 2020.02.25 |
| MNIST를 이용해 간단한 CNN만들기 (2) | 2020.02.12 |
| 배치학습 vs 온라인학습 (0) | 2020.02.12 |