'데이터분석 > 머신러닝' 카테고리의 다른 글
| 엔트로피 (0) | 2023.06.16 |
|---|---|
| TPE 알고리즘 (0) | 2023.06.12 |
| Hyperband (0) | 2023.05.31 |
| 베이지안 최적화(Bayesian Optimization) (0) | 2023.05.31 |
| Feature sore 구축 - Feast (1) | 2023.05.09 |
| 엔트로피 (0) | 2023.06.16 |
|---|---|
| TPE 알고리즘 (0) | 2023.06.12 |
| Hyperband (0) | 2023.05.31 |
| 베이지안 최적화(Bayesian Optimization) (0) | 2023.05.31 |
| Feature sore 구축 - Feast (1) | 2023.05.09 |
Bayesian Optimization 방법은 좋은 성능에 비해 느리다는 단점이 있다. 게다가 sequential하게 진행되는 거라 병렬처리도 어렵다.
이를 개선할 수 있는 방법으로 hyperband가 있으며 빠르며 좋은 성능을 보여준다. Hyperband는 Successive HAlving(SHA) 방법을 기반으로 한다.
Bandit 기반의 하이퍼파라메터 최적화 기법이다. MAB(Multi Armed Bandit)문제를 해결하는데 두가지 방법이 있다.
한가지는 가장 큰 보상을 찾는 팔을 찾는 법, 다른 하나는 Exploitation-Exploration trade-off를 해결하는 것이다.
SHA는 전자인 Best Armed Identification에 기반을 두고 있다.
SHA는 주오진 Budget안에서 hyperparamter 조합을 랜덤하게 선택하여 loss를 평가한다. budget을 늘려가면서 성능이 떨어지는 비율을 정해 hyperparameter조합을 제거해나가는 방법이다. 이 방법은 몇개의 hyperparamter로 시작하지, 어떤 구간에서 줄여나갈지를 정해줘야한다. 이를 개선한것이 hyperband알고리즘이다.

https://pod3275.github.io/paper/2019/05/23/Hyperband.html
Hyperband; A Novel Bandit-Based Approach to Hyperparameter Optimization 정리
Hyperband; A Novel Bandit-Based Approach to Hyperparameter Optimization 정리 저자 : Lisha Li, Kevin Jamieson, Giulia DeSalvo,Afshin Rostamizadeh, Ameet Talwalka...
pod3275.github.io
https://simpling.tistory.com/52
다양한 Hyperparameter Optimization 방법 리뷰
Machine Learning 알고리즘들은 강력한 성능을 보여주고 있다. 하지만 데이터가 커지면서 좋은 HyperParameter(HP)를 찾는 것은 점점 비용이 많이 드는 어려운 문제가 되었다. 보통 찾아야 하는 HP는 여러
simpling.tistory.com
| TPE 알고리즘 (0) | 2023.06.12 |
|---|---|
| 하이퍼파라매터 튜닝 (경험적) (0) | 2023.06.12 |
| 베이지안 최적화(Bayesian Optimization) (0) | 2023.05.31 |
| Feature sore 구축 - Feast (1) | 2023.05.09 |
| Successive Halving Algorithm(SHA) 이해 (0) | 2023.05.02 |
학습을 수행하기 전 hyperparameter설정을 하는데 이때 최적값을 탐색하는 문제해결법을 지칭한다.
방법으로는 Manual, Grid, Random Search와 Bayesian optimization이 있다.
일반적으로 하이퍼파라메터 탐색시 잘 알려진 노하우를 기반하여 hyperparameter를 설정하고 검증데이터셋(validation set)의 측정 결과를 성능으로 기록한다.
여러 시도 중 가장 높은 성능을 준 하이퍼파라메터를 선택했을 것이고 이런 방법을 Manual Search라고 한다.
단점은 찾은 최적의 hyperparameter 값이 ‘실제로도’ 최적이라는 사실을 보장하기가 상대적으로 어렵다는 단점이 있고 또한, 여러 종류의 hyperparameter를 탐색할때 서로간의 상호영향관계를 나타내는 파라메터들도 존재하기 때문에 둘 ㅣ상의 파라메터를 탐색시 직관을 이용하기 어렵고 문제가 더욱 복잡해질 수 있는 단점이 있다.
특정 구간 내의 후보 hyperparameter 값의 일정한 interval을 두고 이들 각각에 대하여 측정한 성능 결과를 기록한 뒤, 가장 높은 성능을 발휘했던 hyperparameter 값을 선정하는 방법이다.
모든 경우의 수에 대해 평가 결과가 가장 좋은 hyperparameter세트를 찾는 방법이다.
전역적인 탐색이 가능하다는 장점이 있지만, hyperparameter개수를 여러종류 가져가면 시간이 기하급수적으로 증가하는 단점이 있다.
탐색 대상 구간 내의 후보 hyperparameter 값들을 랜덤 샘플링(sampling)을 통해 선정한다는 점이 다릅니다.
탐색 대상 구간 내 후보 hyperparameter 값들을 랜덤 샘플링해서 선정하는 방법이다.
Grid Search에 비해 불필요한 반복 수행 횟수를 대폭 줄이면서, 동시에 정해진 간격(grid) 사이에 위치한 값들에 대해 동일한 확률로 탐색이 가능하며 최적의 hyperparameter 값을 더 빨리 찾는 장점이 있다.
랜덤하게 선택하여 학습한 뒤 가장 좋은 parameter를 고를 수 있지만 여전히 불필요한 탐색을 반복하기도 한다.
왜냐하면 다음에 시도할 hyperparameter 값을 선정하는데 이전 정보를 반영하지 않기 때문이다. 이를 개선한 것으로 전체적인 탐색을 가능하게 하며 사전지식까지 반영할 수 있는 Bayesian Optimization이 있다.
입력값 x 를 받은 목적함수 f(x)를 만들어 f(x)를 최대로 만드는 최적해를 찾는 것을 목적으로 한다.
목적함수와 하이퍼파라메터 쌍을 대상으로 대체 모델을 만들고 하이퍼파라메터를 업데이트 해가면서 최적의 조합을 탐색한다.
필요한 요소
- surrogate model은 여러 (x, f(x))로 확률적인 추정을 수행하는 모델이 필요하다.
- Acquisition Function은 확률적 추정 결과를 바탕으로 최적 입력값을 찾는데 있어 가장 유용할만한 다음 입력값을 추천해주는 함수이다.
Expected Improvement(EI)는 Exploitation과 Exploration을 둘다 일정수준 포함하도록 설계한 것이고 이떄 많이 쓰이는게 Acquisition function이다.
| 하이퍼파라매터 튜닝 (경험적) (0) | 2023.06.12 |
|---|---|
| Hyperband (0) | 2023.05.31 |
| Feature sore 구축 - Feast (1) | 2023.05.09 |
| Successive Halving Algorithm(SHA) 이해 (0) | 2023.05.02 |
| Multi-Armed Bandit(MAB) (0) | 2023.05.02 |
[Feast] Feast(Feature Store)란? + Feast 사용법 — Dev study (tistory.com)
[Feast] Feast(Feature Store)란? + Feast 사용법
머신러닝에서 모델을 학습할 때 Raw Data(db, parquet, BigQuery등)에서 Feature를 뽑아서 사용한다. Feature란 테이블의 컬럼 중에서 설명변수(=예측변수)에 해당한다. 1. Feature Store가 필요한 이유 Feature Store
d-yong.tistory.com
| Hyperband (0) | 2023.05.31 |
|---|---|
| 베이지안 최적화(Bayesian Optimization) (0) | 2023.05.31 |
| Successive Halving Algorithm(SHA) 이해 (0) | 2023.05.02 |
| Multi-Armed Bandit(MAB) (0) | 2023.05.02 |
| Sampling method (0) | 2023.04.11 |
| 베이지안 최적화(Bayesian Optimization) (0) | 2023.05.31 |
|---|---|
| Feature sore 구축 - Feast (1) | 2023.05.09 |
| Multi-Armed Bandit(MAB) (0) | 2023.05.02 |
| Sampling method (0) | 2023.04.11 |
| 다이렉트 마케팅에 사용되는 Uplifting modeling (0) | 2023.03.30 |
Multi-Armed Bandit algorithm은 굉장히 Profitable한 모델이며 이해하기가 쉽다.
카지노 게임장에서 가장 유리한 슬롯을 찾는것부터 시작됐으며, Arm은 슬롯에 잡아당기는 부분, Bandit(노상강도)는 슬롯, 그리고 여러개의 슬롯중 최적의 효율을 내는 것을 탐색하기 위해 Multi-Armed Bandit이 탄생했다.
문제: 탐험(Exploration)이 충분히 이루어지지 않음

동전의 확률은 50:50이다. 50%의 확률로 greedy알고리즘에서 가장 좋았던 슬롯머신을 선택하고, 50%확률로 동전 뒷면이 나오면 슬롯과 상관없이 랜덤하게 골라서 한다. 여기서, 입실론이 하이퍼파라메터이다.


기존에 greedy알고리즘과 비교하면, 빨간 박스가 추가되었다. 해당 슬롯머신이 최적의 슬롯머신이 될 수 있는 가능성이다.
| Feature sore 구축 - Feast (1) | 2023.05.09 |
|---|---|
| Successive Halving Algorithm(SHA) 이해 (0) | 2023.05.02 |
| Sampling method (0) | 2023.04.11 |
| 다이렉트 마케팅에 사용되는 Uplifting modeling (0) | 2023.03.30 |
| 자동화 시스템 구축을 위한 AutoML (0) | 2023.03.30 |
1. simple random sampling: 난수표를 이용해 모든 대상이 동일한 기회를 갖도록 추출되는 방법
2. stratified random sampling: 일정 기준에 따라 2개 이상의 동질적 층으로 구분하여 층별로 추출되는 방법.
중요 집단을 빼지 않고 표본에 포함시킬 수 있으므로 대표성이 높음. 기존 비율을 유지한 채로 추출.
3. systematic random sampling: 무작위 위치에서 출발점을 선택하고 각 k번째인 데이터로 추출하는 방법. 데이터 개수가 많다면, 단순무작위표본추출에 비해서는 대표성이 높음.
4. cluster sampling : 모집단의 대상을 직접 추출하지 않고 여러 개의 cluster로 묶어서 cluster를 추출해 군집내 대상을 조사하는 방법.
단순표본추출에서 현실적으로 제약이 있을때 이용될 수 있음.
참고자료: 표본추출 (tistory.com)
표본추출
1. 표본추출이란? 그림1.1 모집단으로부터 표본추출과정 표본이란 연구대상 전체에서 선택된 일부를 말하며, 이런 표본을 선택하는 과정을 표본추출(표집)이라고 말한다. 표본추출에서는 표본이
bohemian0302.tistory.com
| 다중공선성 제거: X변수 축소 (0) | 2023.08.25 |
|---|---|
| Feature selection? sklearn을 활용하면 (0) | 2023.07.19 |
| 평가지표 (1) Accuracy와 Precision and Recall (0) | 2021.08.02 |
| 데이터 불균형 문제를 대하는 법 - Sampling 방법론 (0) | 2021.04.13 |
| 표준화(standardization)와 정규화(normalization) (0) | 2021.01.27 |
데이터 양을 절대적으로 줄여 모델 적합 시간을 줄이되, 정보손실을 최소화할 수 있는 방법론을 탐색한다.
1. Probability Sampling: 랜덤하게 데이터를 추출하는 방법, 모집단의 모든 구성원이 선택될 가능성이 있는 추출
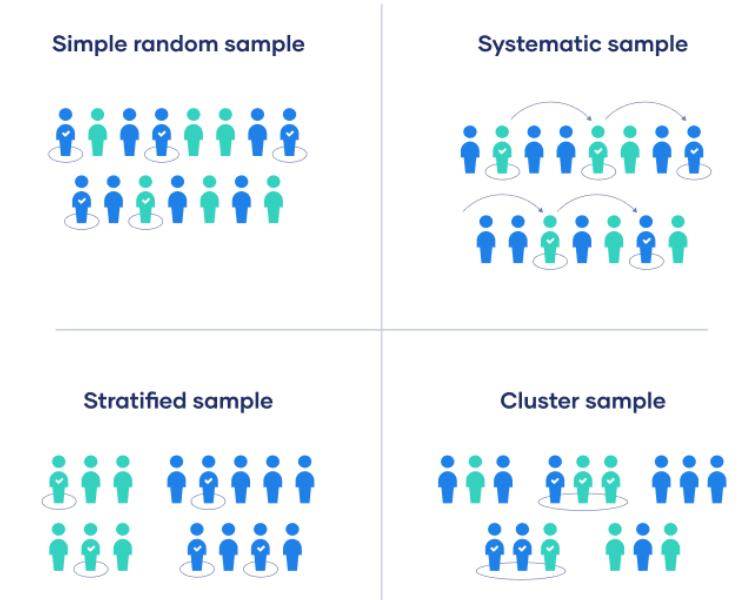
1) simple random sampling: 랜덤한 숫자를 줘서 무작위 추출
- python 함수: pandas.sample
2) systematic sampilng: 어떤 체계를 주어 무작위 추출 (예시: 6번째마다 추출, 문제점: 데이터의 순서에 따른 정보가 담겨 있으면 안됨)
- python 함수 (step size를 만들어 일정 구간의 데이터를 추출)
3) stratified sampling: 모집단을 n개의 그룹으로 나눠 임의로 k개의 데이터를 추출해서 합치는 방법
- python 함수: from sklearn.model_selection import StratifiedSuffleSplit
4) cluster sampling: 모집단을 여러개의 군집으로 나눠 군집 k개를 선택해 합치는 방법
- python 함수: cluster를 설정해 랜덤하게 추출
simple-random-sampling | Kaggle
simple-random-sampling
Explore and run machine learning code with Kaggle Notebooks | Using data from Credit_data
www.kaggle.com
2. Non-Probability Sampling : 랜덤하지 않게 데이터를 추출하는 방법

1) convience sampling: 데이터를 수집하기 좋은 위치나 시기에 샘플링함 ( 통계적 추론 불가)
2) purposive sampling: 목적에 가장 적합한 데이터라고 생각하는 샘플 선택 (모집단의 대표성이 떨어짐)
3) quota sampling:
연구편향을 최소화하기 위해 샘플링 단계를 명확히 해야함. 대표 샘플이 부족한 경우 연구편향이 일어나거나 유효성에 영향을 미침.
1. 데이터 세트가 줄어든다고 잃어버린 정보량을 측정할 방법은 없음
1. k-최근접 이웃 알고리즘으로 다수의 clustering을 만든뒤 각 cluster별로 차이가 없다고 생각될때 하나의 cluster를 선택해서 학습
Prototype Reduction in Nearest Neighbor Classification: Prototype Selection and Prototype Generation | Soft Computing and Intell
sci2s.ugr.es
2. 밀도 보존 샘플링: 세트를 무작위로 선택하거나 층화된 그룹을 찾는 법
https://ieeexplore.ieee.org/stamp/stamp.jsp?arnumber=6360017
IEEE Xplore Full-Text PDF:
ieeexplore.ieee.org
3. 가장 간단한 무작위 샘플링
- 이해하기 쉽고 실수하기 어려우며 프로세스에 편향을 도입할 가능성이 없음.
- 여러 샘플들을 실험해보고 전체 데이터 세트에 대해 다시 실행하여 성능 향상을 추정해보면 됨
- 단순 샘플링으로 데이터 개수를 늘려가면서 robustness를 찾는 법도 괜찮음
교육 속도와 정확도 대 예제 수의 장단점을 보여주는 그래프는
https://github.com/szilard/benchm-ml
GitHub - szilard/benchm-ml: A minimal benchmark for scalability, speed and accuracy of commonly used open source implementations
A minimal benchmark for scalability, speed and accuracy of commonly used open source implementations (R packages, Python scikit-learn, H2O, xgboost, Spark MLlib etc.) of the top machine learning al...
github.com
Cleanlab Open-Sources ActiveLab: A Novel Active Learning Method For Data Labeling To Improve Machine Learning Models
Labeled data is essential for training supervised machine learning models, but mistakes made by data annotators can impact the model's accuracy. It is common to collect multiple annotations per data point to reduce annotation errors to establish a more rel
www.marktechpost.com
https://github.com/cleanlab/cleanlab
GitHub - cleanlab/cleanlab: The standard data-centric AI package for data quality and machine learning with messy, real-world da
The standard data-centric AI package for data quality and machine learning with messy, real-world data and labels. - GitHub - cleanlab/cleanlab: The standard data-centric AI package for data qualit...
github.com
GitHub - cleanlab/examples: Notebooks demonstrating example applications of the cleanlab library
Notebooks demonstrating example applications of the cleanlab library - GitHub - cleanlab/examples: Notebooks demonstrating example applications of the cleanlab library
github.com
데이터가 추가됨에 따라 성능의 robustness를 보인다면 cut-off를 하는 방법
ADP) 3-2. 파이썬으로 표본 추출: 단순랜덤 추출법, 계통추출법, 집락추출법, 층화추출법 (tistory.com)
ADP) 3-2. 파이썬으로 표본 추출: 단순랜덤 추출법, 계통추출법, 집락추출법, 층화추출법
파이썬으로 표본 추출 (Sampling) 하기 단순랜덤추출법 (simple random sampling) 각 샘플에 번호를 부여하여 임의의 n개를 추출하는 방법으로 각 샘플은 선택될 확률이 동일하다. 추출한 element를 다시 집
lovelydiary.tistory.com
Sample_size_estimation_and_sampling_tech (1).pdf
0.30MB
Sampling_Methods_and_its_Comparison_Data (1).pdf
0.49MB
comparison_of_sampling_techniques (1).pdf
0.30MB
| Successive Halving Algorithm(SHA) 이해 (0) | 2023.05.02 |
|---|---|
| Multi-Armed Bandit(MAB) (0) | 2023.05.02 |
| 다이렉트 마케팅에 사용되는 Uplifting modeling (0) | 2023.03.30 |
| 자동화 시스템 구축을 위한 AutoML (0) | 2023.03.30 |
| Decision tree (0) | 2022.06.29 |