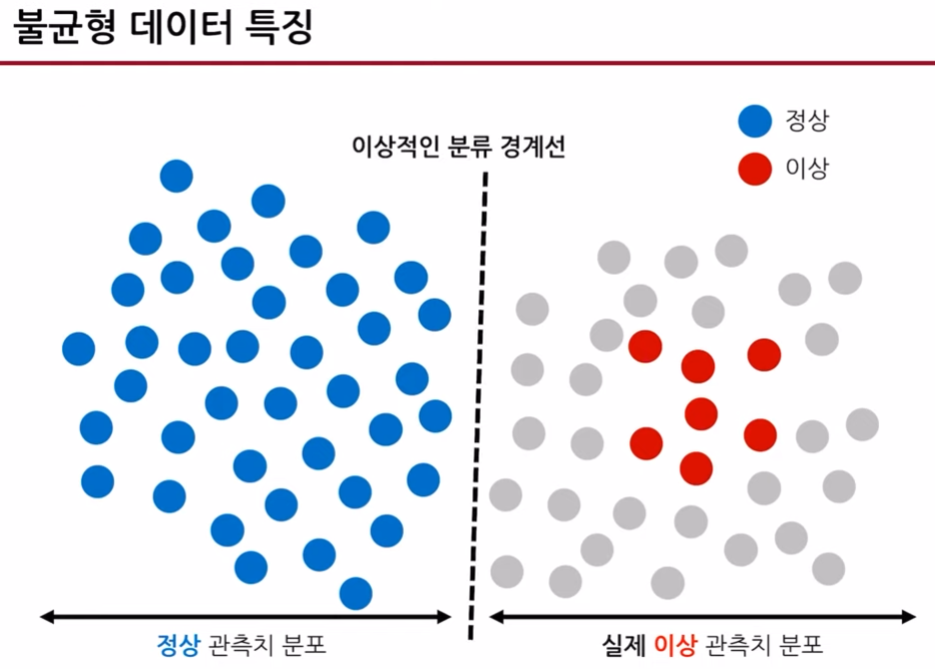
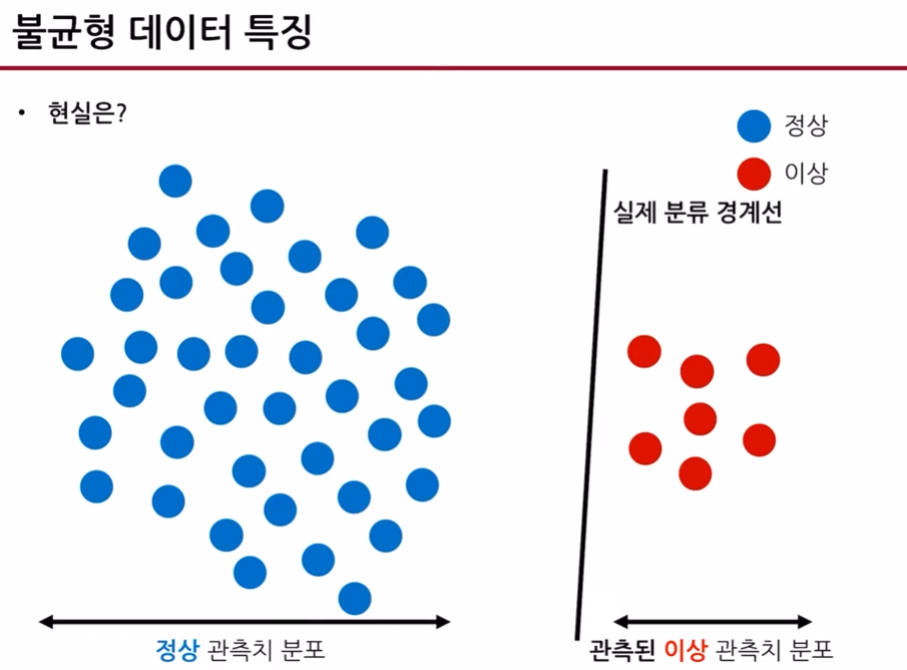
abundant class(주로 정상데이터)와 rare class(이상데이터 그룹)의 비율이 1:99와 같이 극단적인 경우가 발생하는 경우,
크게 두가지 방법으로 모델의 잘못된 판단을 막을 수 있습니다.
1. sampling을 하는 것
2. 모델의 cost를 주어 모델 내에서 개선하는 방법
이번 포스팅에서는 sampling중 down-sampling과 up-sampling의 방법론들을 다룰 것 입니다.
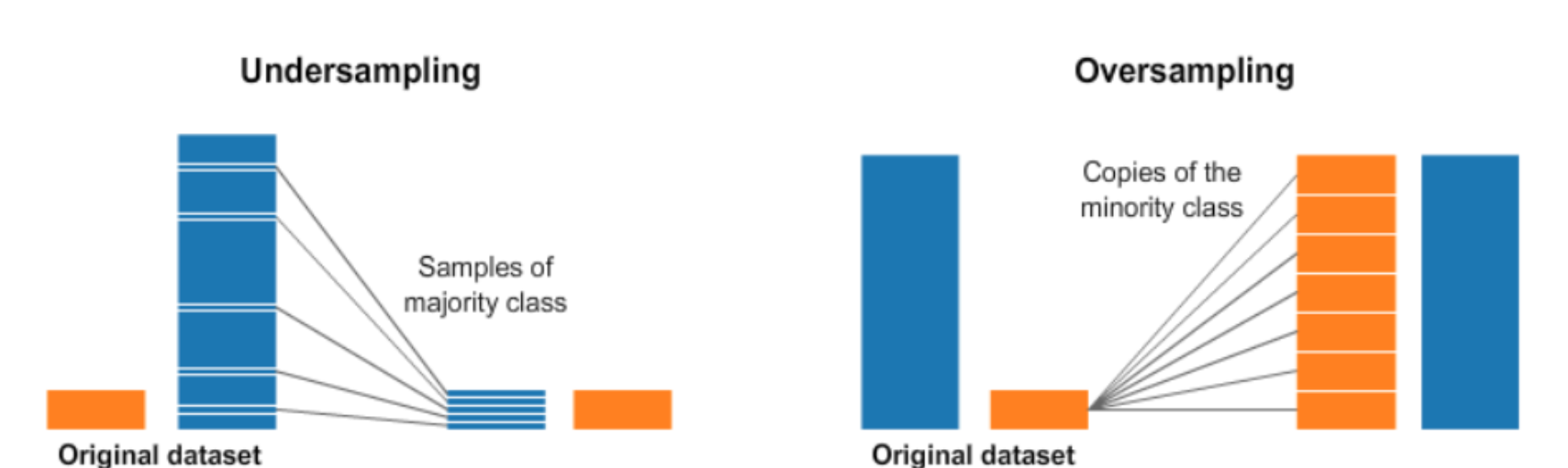
1. Down-sampling
Under-sampling의 장점은 필요없는 데이터를 지우기 때문에, 계산시간이 빠르지만 단점은 지워진 데이터들로 인해 정보손실이 발생할 수 있습니다.
- random down-sampling: 랜덤하게 abundant class의 instance를 추출해서 rare class와 1:1 비율을 맞춘 데이터 셋으로 학습시킵니다. 매번 랜덤하게 샘플링되기 때문에 경계선이 달라져 결과가 달리나오지만 꽤나 좋은 모델로 평가받고 있습니다.
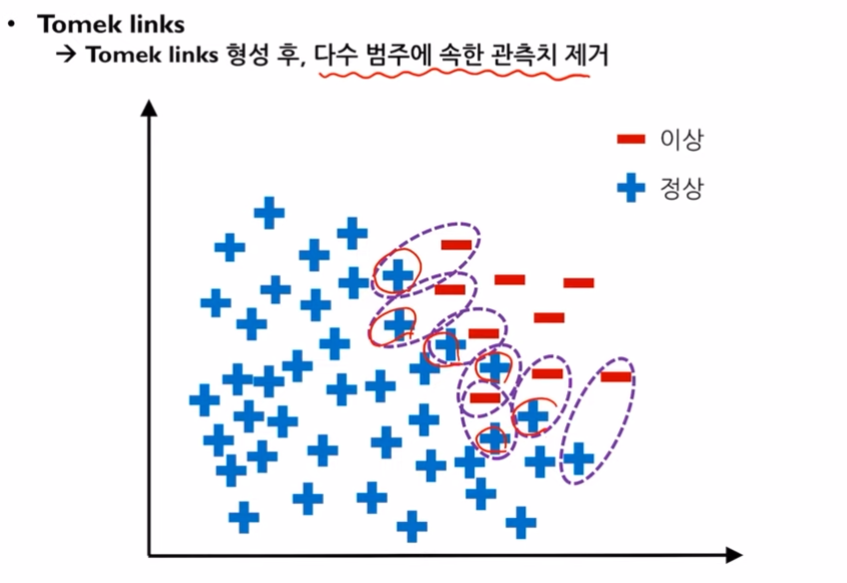
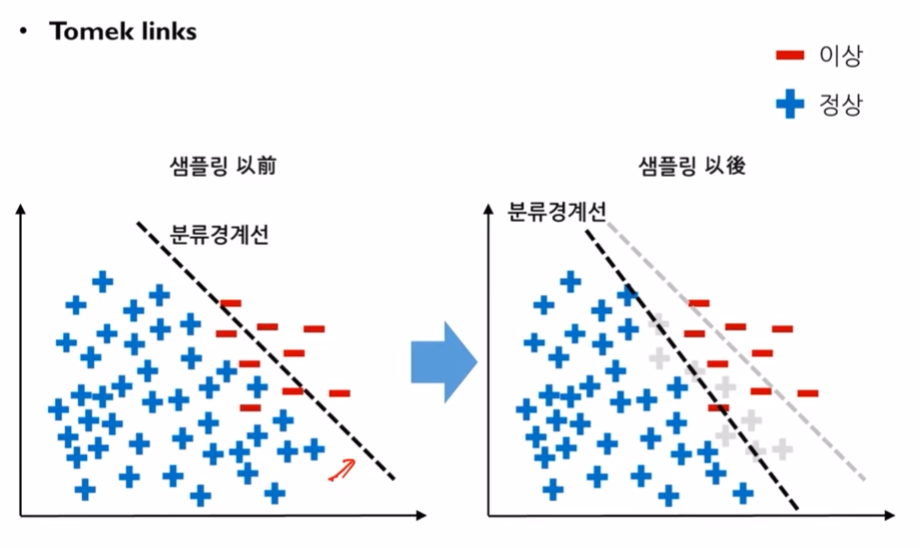
- Tomek links down-sampling: Tomek-links라는 것은 abundant class의 instance와 rare class의 instance를 2차원 평면에 뿌렸을 때, 둘 사이를 직선으로 열결했을때 이를 방해하는 다른 instance가 없을 경우에 그 직선을 말합니다. 이때, Tomek-links에 연결된 정상데이터들을 지움으로써 분류경계선을 새로 그을 수 있게 됩니다.
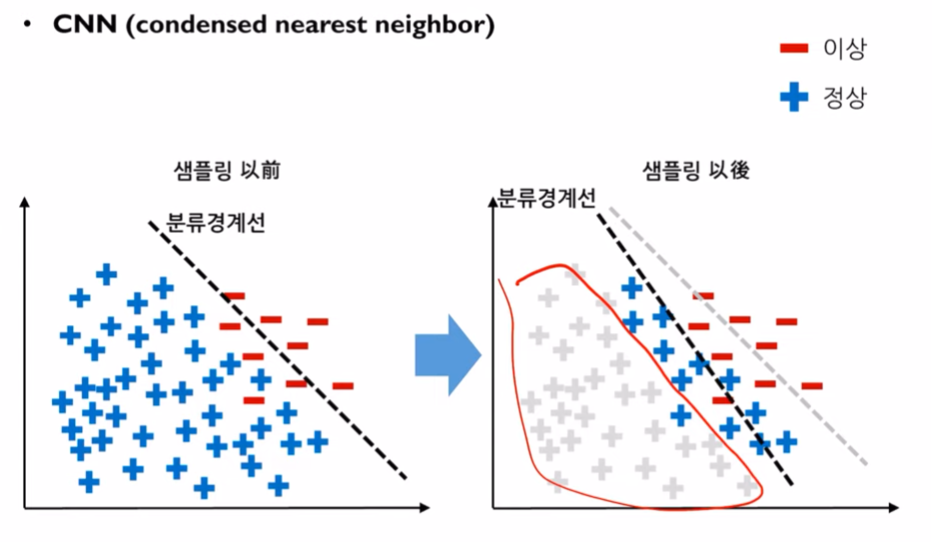
- CNN(Condensed Nearest Neighbor) : 1-NN를 사용해서 abundant와 rare사이의 1개의 관측치를 골라서 어떤 그룹에 더 가까운지 판단하여 가까운 그룹에 데이터로 속하게 함. 만약, rare class에 가깝다면 abundant class의 instance를 rare로 변경하고, 나머지 abundant class data를 모두 지웁니다. 그 후, rare class로 분류되었던 abundant class의 data를 다시 abundant class로 변경해줍니다. 이때, 사용하는 NN은 k-NN이 아닌 무조건 1-NN을 사용해야합니다.
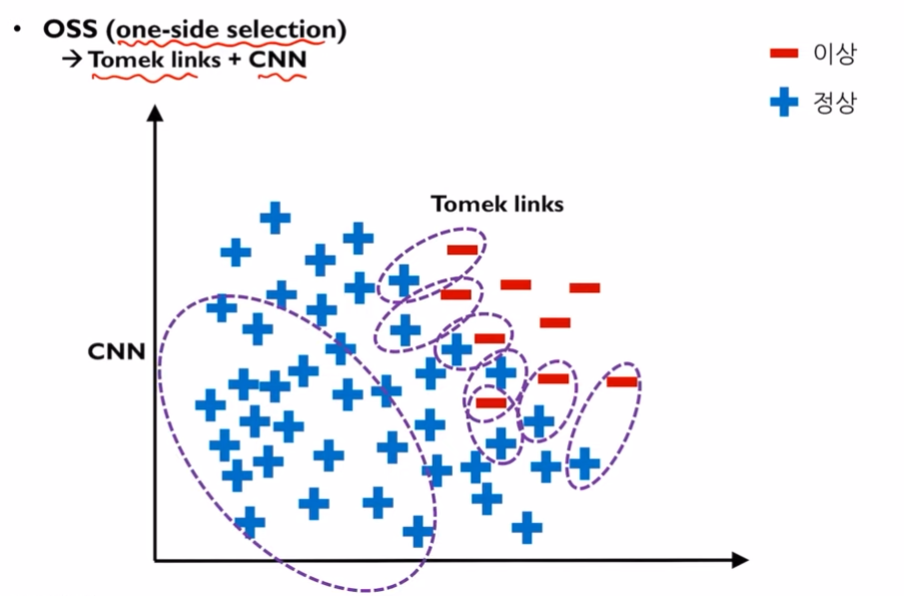
- OSS: Tomet-links에서 나온 under-sampling 데이터와, CNN에서 나온 under-sampling데이터를 합치는 것입니다. OSS
2. Over-sampling
단점: 소수클래스에 과적합이 생길 수 있습니다.
- Resampling: rare class의 instance를 랜덤복원추출하여 데이터를 증가시키는 방법입니다.
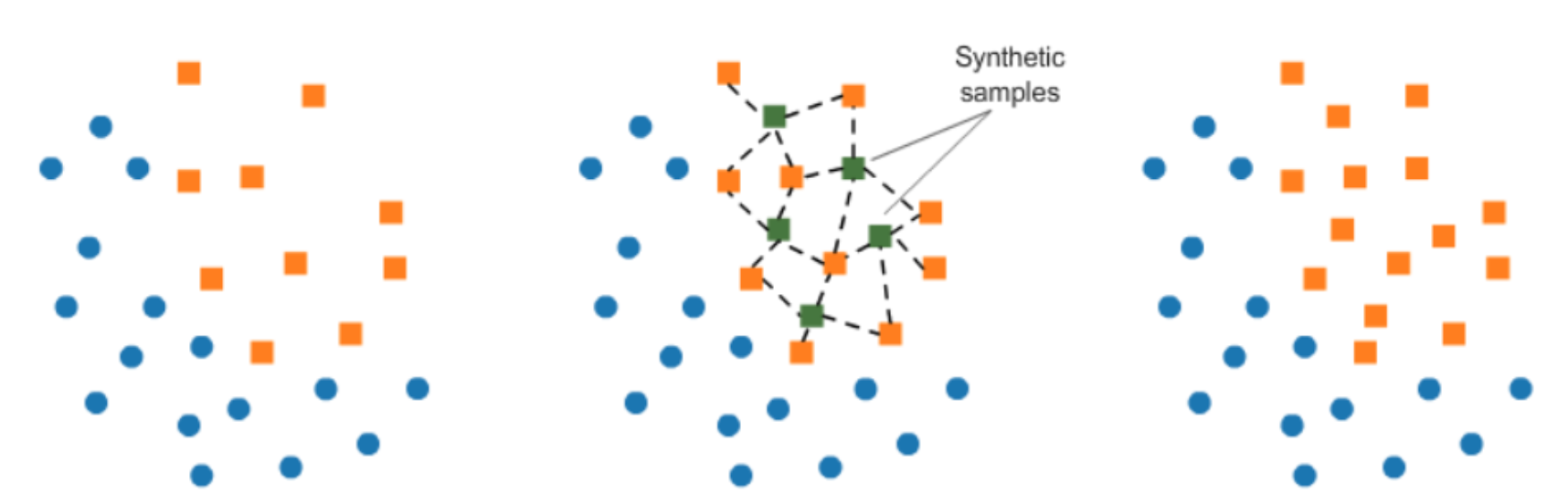
- SMOTE (Sythetic Minority Oversampling technique): resampling 했을때 over-fitting되는 문제를 해결하기 위해 나온 방법론으로 up-sampling에서 주로 사용되는 방법입니다.
- Boarderline SMOTE: 경계부분에서 over-sampling을 하는 방법입니다. 이상데이터와 정상데이터 사이의 데이터들 위주로 증폭시키기 위한 방법입니다. 사실, 전체 정상데이터와 이상데이터 사이에 SMOTE를 사용하면, 경계선 주변부에 데이터들이 생성되는것이외에 이상데이터 바깥쪽에도 데이터가 생성될 가능성이 높습니다. 하지만, 이런 데이터들은 모델을 학습시키기에 좋은 데이터들은 아니기 때문에 경계선 주위에 데이터를 생성할 수 있도록, 경계선 주위의 정상데이터들로 SMOTE샘플링을 하는 방법입니다.
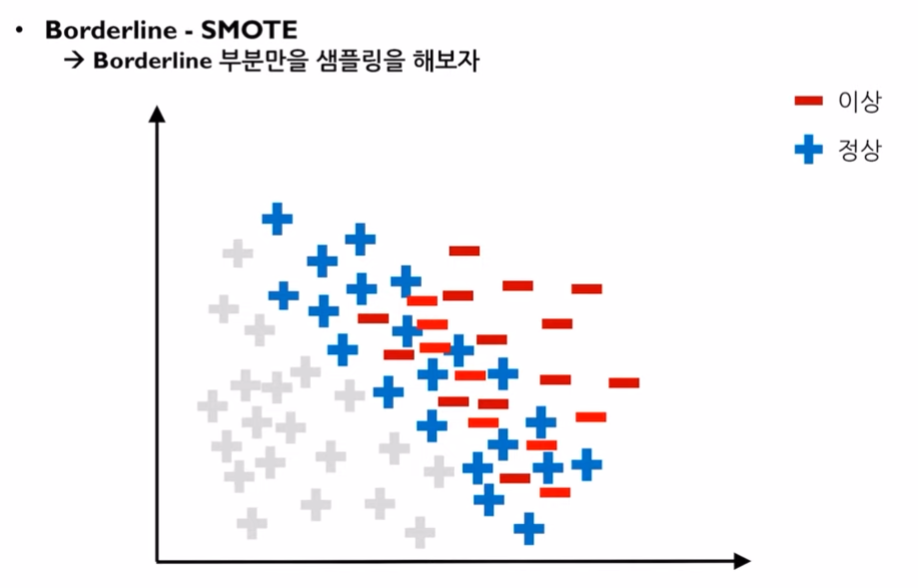
여기서?
컴퓨터가 Boarderline을 판단하는 방법은, k를 정해 그룹핑을 하여 k개의 데이터가 모두 소수 관측치라면 이를 'safe 관측치'라고 부릅니다. 그리고 이것은 boarderline이 될 수 없습니다.
하지만, 다른 k개의 그룹을 했을때, 다수 관측치가 k/2이상이라면 이를 boarderline이라고 하며 'danger 관측치'라고 부릅니다. k개의 그룹에서 다수의 데이터가 또 너무 많이 존재할 경우 이를 'noise 관측치'라고 합니다.
따라서, Boarderline SMOTE sampling의 경우에는 danger 관측치에서 SMOTE sampling을 하는것을 말합니다.
- ADASYN(Adaptive Synthetic sampling approach):
<인공지능공학소의 김성범 소장님의 강의를 참고하여 작성합니다. >
python 비대칭 데이터 문제 해결:
비대칭 데이터 문제 — 데이터 사이언스 스쿨
데이터 클래스 비율이 너무 차이가 나면(highly-imbalanced data) 단순히 우세한 클래스를 택하는 모형의 정확도가 높아지므로 모형의 성능판별이 어려워진다. 즉, 정확도(accuracy)가 높아도 데이터 갯
datascienceschool.net
'데이터분석 > 전처리' 카테고리의 다른 글
| Feature selection? sklearn을 활용하면 (0) | 2023.07.19 |
|---|---|
| Sampling 방법 (0) | 2023.04.28 |
| 평가지표 (1) Accuracy와 Precision and Recall (0) | 2021.08.02 |
| 표준화(standardization)와 정규화(normalization) (0) | 2021.01.27 |
| PCA - 주성분 분석 (0) | 2020.11.16 |