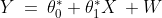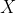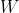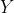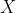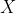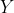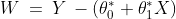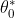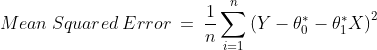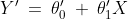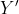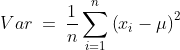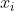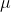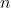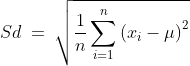Let’s start with an example: Suppose you're given a dataset that contains thesize (in terms of area) of different houses and their market price. Your goal is to come up with an algorithm that will take thesize of the house as its inputandreturn its market price as the output.
In this example, the input variable i.e the size of the house, is called the independent variable (X), the output variable i.e house price is called the dependent variable (Y), and this algorithm is an example ofsupervised learning.
In supervised learning,algorithms are trained using "labeled"data (in this example, the dependent variable - house price, is considered a label for each house), and trained on that basis, the algorithm can predict an output for instances where this label (house price) is not known. "Labeled data" in this context simply means that the data is alreadytaggedwith the correct output. So in the above example, we already know the correct market price for each house, and that data is used to teach the algorithm so that it can correctly predict the house price for any future house for which the price may not be known.
The reason this paradigm of machine learning is known as supervised learning, is because it is similar to the process of supervision that a teacher would conduct on the test results of a student on an examination, for example. The answers the student gives (predictions) are evaluated against the correct answers (the labels) that the teacher knows for those questions, and the difference (error) is what the student would need to minimize to score perfectly on the exam. This is exactly how machine learning algorithms of this category learn, and that is why the class of techniques is known as supervised learning.
There are mainly 2 types of supervised learning algorithms:
Regression,where your output variable is acontinuousvariable, for example, the price of a house.
Classification, where your output variable iscategorical, for example, approve the loan or not i.e. yes or no categories.
In this lecture, we will be learning about regression algorithms, which obviously find great use in the machine learning prediction of several numerical variables we would be interested in estimating, such as price, income, age, etc.
Linear Regression
Linear Regression is useful for finding thelinear relationshipbetween theindependent and dependentvariables of a dataset. In the previous example, the independent variable was the size of the house and the dependent variable its market price.
This relationship is given by the linear equation:
Where
is theconstantterm in the equation,
is thecoefficientof the variable
,
is the difference between the actual value
and the predicted value(
).
and
are called the parameters of the linear equation, while
and
are the independent and dependent variables respectively.
What is an error?
With given
and
in the training data, the aim is to estimate
and
in such a way that the given equationfitsthe training datathe best. Thedifferencebetween theactual value and the predicted valueis called theerror or residual. Mathematically, it can be given as follows:
In order to estimate the best fit line, we need to estimate the values of
and
which requires minimizing themean squared error. To calculate the mean squared error, we add the square of each error term and divide the sum with the total number of records:
The equation of that best fit line can be given as follows:
Where
is the predicted value,
are the estimated parameters.
This equation is called thelinear regression model. The above explanation is demonstrated in the below picture:
Before applying the model over unseen data, it is important to check its performance to make it reliable. There are a few metrics to measure the performance of a regression model.
R-squared:R-squared is a useful performance metric to understandhow wellthe regression model hasfitted over the training data. For example, an R-squared of80%reveals that 80% of thetraining datafit the regression model.A higher R-squaredvaluegenerallyindicates abetter fit for the model.
Adjusted R-squared: The adjusted R-squared is amodifiedversion of R-squared that takes into account thenumber of independent variables present in the model. When a new variable is added, adjusted R-squaredincreasesif that variableadds valueto the model, anddecreasesif itdoes not. Hence, adjusted R-squared is a better choice of metric than R-squared to evaluate the quality of a regression model with multiple independent variables, because adjusted R-squared only remains high when all those independent variables are required to predict the value of the dependent variable well; it decreases if there are any independent variables which don't have a significant effect on the predicted variable.
RMSE: RMSE stands forRoot Mean Squared Error. It is calculated as the square root of the mean of the squared differences between actual outputs and predictions. The lower the RMSE the better the performance of the model. Mathematically it can be given as follows:
Acontinuous variable can take aninfinite numberofdistinct numericalvalues, possibly in agivenrangeof numbers. For example, theMonthly Incomeof employees in a certain firm is a continuous variable.
Acategorical variable, on the other hand, can take only a limited (finite) number of distinct values. For example, in an image dataset of single handwritten digits, the digit in the image would be a categorical variable because it can only take a finite number of distinct values, in this case from 0 to 9, and nothing beyond that.
Dependent and Independent Variables
In data science, given a set of variables, we need toestablishthe relationship between one variable and others. The variable to be estimated isdependenton the rest of the variables and hence called thedependent variable, while the remaining variables that affect the dependent variable are calledindependent variables.
For example, if we have 4 featuresAge, Education Level, Work Experience,and Salary, and need to find the relation between the Salary and the rest of the features, the Salary would be thedependent variable while Age, Education Level, and the Work Experience would beindependent variables.
Variance and Standard Deviation
In statistics, it is important to understand themagnitude of the spreadof the observed data from theMean.
VarianceandStandard Deviationare two quantities that address this concept. To calculate the variance, we take the difference between each number in the dataset and the mean of the data, square this difference to make it positive (independent of sign), and finally divide the sum of the squares by the total number of values in the dataset.
Mathematically, thevariance of the populationcan be given as follows:
Where
is a data point,
is the population mean, and
is the total number of data points.
One of the major drawbacks of using variance, to understand the spread of the data, is its interpretability. The unit of variance is the square of the original unit of the data. To overcome this, another quantity is introduced, which is thesquare rootof the variance. This is called thestandard deviation of the population.
Mathematically, thestandard deviationof the populationcan be given as follows:
Being the square root of the variance, the standard deviation is more interpretable, having the same units as the original data points. The standard deviation is able to give a sense for the measure of the spread of the dataset around its mean.
Confidence Interval
Inferential statistics is associated with estimating the populationparametersby extracting samples from the same population. In general, when we make an estimate about some quantity of the population (for example, mean), we come up with a single number. This single number is called apoint estimate.For example, if we take a sample from a population and the sample mean is 35, then it is expected that the population mean is also 35. The drawback of point estimates is that we do not knowhow surewe are that the population mean is 35.
To increase the certainty of our estimate, we associate it with another concept known as the confidence interval.
A confidence interval is arange of values from the point estimate, where we assume that thepopulation parameter will lie in this range with acertain percentage of confidence.
Let’s consider an example:Suppose we are extracting 100 samples from a group of students in a university, where each sample has a certain number of records. We have calculated the mean age of students from each sample. Now, if we say that the confidence interval is [18, 24] with a 95% probability, then it means that the mean age of95 out of 100samples will lie in the range of 18-24.
The higher the confidence, the more the width of the confidence interval.